
Introduction: The New Era of Intelligent Data
The data landscape is undergoing a fundamental shift. For decades, databases were designed to store, organize, and retrieve data efficiently — powering transactions and analytics behind the scenes.
But today, in the age of Artificial Intelligence (AI) and Machine Learning (ML), that model is no longer enough. Modern applications demand systems that understand, reason, and respond to context in real time. To meet this demand, databases are evolving from passive data stores into active intelligence layers that are capable of generating insights, predictions, and recommendations directly where the data lives.
AWS has been steadily building toward this vision. Through innovations such as Aurora ML, pgvector in Amazon Aurora and RDS, Amazon Redshift ML, OpenSearch vector search, and Neptune ML, AWS databases are becoming truly AI-ready.
What Makes a Database AI-Ready
An AI-ready database is built to do more than just store data. It’s designed to make that data usable for artificial intelligence. While it continues to support database engine native data types, it also handles AI-native data such as vector embeddings used for semantic search and retrieval-augmented generation (RAG). It connects seamlessly to ML models for training, deployment, and real-time inference, turning a traditional database into an active part of the AI workflow where learning and prediction happen close to the data itself.
Key characteristics include:
- Native ML integration: Invoke ML models directly from SQL queries to reduce data movement and latency.
- Vector embedding support: Store and query embeddings that represent semantic meaning, enabling similarity and context-aware search.
- Streaming and real-time readiness: Integrate with services such as Amazon Kinesis or Managed Streaming for Apache Kafka (MSK) to process events as they happen.
- Elastic compute and storage: Scale automatically to handle training, inference, or vector workloads as data grows.
- Strong governance and security: Apply IAM roles, encryption, and data lineage tracking to maintain compliance and trust.
AI and ML Capabilities Across AWS Databases
As organizations embrace AI and machine learning, AWS databases are evolving to make intelligence a native part of data infrastructure. From real-time inference to semantic search and retrieval-augmented generation (RAG), these systems now go far beyond traditional storage and querying.
Let’s explore how AWS databases, from Aurora to S3, are becoming AI-ready, enabling applications that understand context, reason over data, and deliver insights directly where information lives.
Amazon Aurora ML (with Bedrock, SageMaker, and Comprehend)
Amazon Aurora ML integrates directly with Amazon Bedrock, SageMaker, and Comprehend, allowing ML inference within SQL statements.
For example, the following SQL query performs model inference directly inside the database:
SELECT customer_id,
ml_infer_sagemaker('loan-risk-model', income, debt, credit_score) AS risk_score
FROM loan_applications;
By integrating Aurora ML with AWS AI services such as Bedrock, SageMaker, and Comprehend, you can embed machine learning directly into your transactional workloads, enabling real-time predictions, anomaly detection, and intelligent automation without moving data outside the database.
pgvector in Amazon Aurora & Amazon RDS for PostgreSQL
Amazon now supports pgvector in both Aurora PostgreSQL and RDS for PostgreSQL, enabling you to store, index, and query high-dimensional embeddings directly within the database. This allows developers to perform semantic search and similarity queries natively, without relying on external vector stores. With pgvector, you can store embeddings generated from Amazon Bedrock, SageMaker, or other ML models, and use operators such as <-> to calculate similarity between vectors.
For example, the following query retrieves the five most similar documents based on vector similarity:
SELECT id, content
FROM documents
ORDER BY embedding <-> '[0.13, 0.27, 0.42, ...]'::vector
LIMIT 5;
By integrating pgvector with AWS AI services, you can build applications that combine traditional SQL queries with semantic search, powering use cases like retrieval-augmented generation (RAG), intelligent search, and personalized recommendations, all within your Aurora or RDS PostgreSQL environment.
Amazon Redshift ML and Bedrock Integration
Amazon Redshift extends its analytical power with Redshift ML, allowing you to build and run machine learning models directly in SQL, without exporting data or managing separate ML infrastructure. It integrates with Amazon SageMaker Autopilot for automated model training and now supports Amazon Bedrock to enable generative AI (GenAI) capabilities like text summarization, classification, and conversational insights.
Redshift ML uses data already stored in your warehouse to train and host predictive models in SageMaker, while keeping the entire workflow accessible through familiar SQL syntax. This eliminates data movement, reduces complexity, and brings predictive intelligence closer to your analytics layer.
For example, the following command trains a customer churn prediction model directly in Redshift:
CREATE MODEL churn_model
FROM (SELECT age, tenure, charges, churn FROM customers)
TARGET churn
FUNCTION predict_churn
IAM_ROLE 'arn:aws:iam::123456789012:role/RedshiftMLRole';
Once deployed, you can invoke the model within any query for real-time predictions, just like any other SQL function.
Amazon OpenSearch Service & Serverless (Vector Search)
Amazon OpenSearch Service and OpenSearch Serverless offer native vector search capabilities that combine semantic understanding with traditional keyword queries, enabling hybrid search (a blend of keyword and vector-based relevance) and retrieval-augmented generation (RAG) use cases, where vector search provides contextual data to generative AI models.
Vector search collections in OpenSearch store embeddings, which are vector representations of data generated by Amazon Bedrock, SageMaker, or other ML models. These embeddings make it possible to run semantic and similarity-based queries that go beyond exact keyword matches. You can perform approximate nearest neighbor (ANN) searches to find documents, products, or conversations that are most relevant in meaning, not just text.
For example, the following query retrieves the five most similar documents based on vector similarity:
POST /my-index/_search
{
"query": {
"knn": {
"embedding": {
"vector": [0.25, 0.11, 0.78, ...],
"k": 5
}
}
}
}
OpenSearch also supports hybrid queries, blending keyword and vector-based relevance for more contextual results. Serverless mode automatically scales vector workloads without cluster management, making it ideal for dynamic or high-traffic AI applications. By integrating with Amazon Bedrock or SageMaker, you can automate embedding generation and indexing, creating fully managed pipelines for semantic search, RAG, and personalized content retrieval within AWS.
Amazon Neptune ML and Neptune Analytics
Amazon Neptune ML brings machine learning to graph databases by using the Deep Graph Library (DGL) and Amazon SageMaker to train and deploy graph neural networks (GNNs) without complex pipelines. It learns from the connections between data, not just the attributes, to predict relationships, detect anomalies, and generate intelligent recommendations.
Neptune Analytics extends these capabilities with vector search powered by HNSW indexing, enabling semantic similarity queries across graph embeddings. This makes it easier to find related entities and enrich retrieval-augmented generation (RAG) pipelines with graph-aware context.
Together, Neptune ML and Neptune Analytics turn traditional graph queries into intelligent, context-aware reasoning that powers applications such as fraud detection, recommendation systems, and knowledge graphs.
Amazon DocumentDB (MongoDB-Compatible): Vector Search
Amazon DocumentDB now supports native vector search, allowing you to store and query vector embeddings within JSON documents. This capability makes it possible to combine structured and unstructured data to enable semantic search, retrieval-augmented generation (RAG), and AI-powered chatbots, all without moving data to a separate vector database.
DocumentDB integrates seamlessly with Amazon Bedrock and SageMaker for embedding generation. You can store embeddings directly in your collections and use vector similarity operators to retrieve contextually relevant documents or responses.
By unifying document storage and semantic retrieval, DocumentDB simplifies building knowledge-based applications, content search systems, and intelligent assistants that operate efficiently at scale.
Amazon MemoryDB for Redis: In-Memory Vector Search
Amazon MemoryDB for Redis now supports in-memory vector search, combining the speed of Redis with AWS scalability for real-time semantic retrieval. You can store and query embeddings using cosine, Euclidean, or dot product similarity, making it ideal for personalization, recommendations, and semantic caching.
Running entirely in memory, MemoryDB delivers microsecond latency for vector lookups. It integrates seamlessly with Amazon Bedrock, SageMaker, and AWS Lambda through standard Redis clients, making it easy to generate, store, and retrieve embeddings at scale.
This makes MemoryDB a powerful choice for low-latency AI inference, session-based personalization, and context-aware chat applications that demand instant vector search performance
Amazon DynamoDB + OpenSearch: Zero-ETL for Vectors
Amazon DynamoDB doesn’t store vectors natively, but through its zero-ETL integration with Amazon OpenSearch Service, you can automatically sync structured data to OpenSearch for semantic and vector-based queries.
This integration allows you to enrich DynamoDB records with embeddings generated from Amazon Bedrock or SageMaker, then query them in OpenSearch using hybrid or vector similarity search, all without building custom pipelines or data movement scripts.
By combining DynamoDB’s scalability with OpenSearch’s vector search and analytics capabilities, you can build real-time, AI-powered applications that unify transactional and semantic data. This makes it ideal for personalization, recommendation engines, and intelligent search experiences.
Amazon S3 Vectors (Preview)
Amazon S3 Vectors introduces a new way to store and search embeddings directly in Amazon S3, turning object storage into a large-scale vector data lake. Currently in preview, it allows you to manage billions of embeddings without standing up a separate vector database or index service.
You can use Amazon Bedrock, SageMaker, or other ML models to generate embeddings and store them as vector objects in S3. These vectors can then be queried using similarity search APIs for semantic retrieval across documents, images, or other unstructured data stored in your buckets.
By combining S3’s scalability and durability with vector search, Amazon S3 Vectors lays the foundation for long-term embedding storage and large-scale retrieval-augmented generation (RAG) pipelines that integrate seamlessly with other AWS AI services.
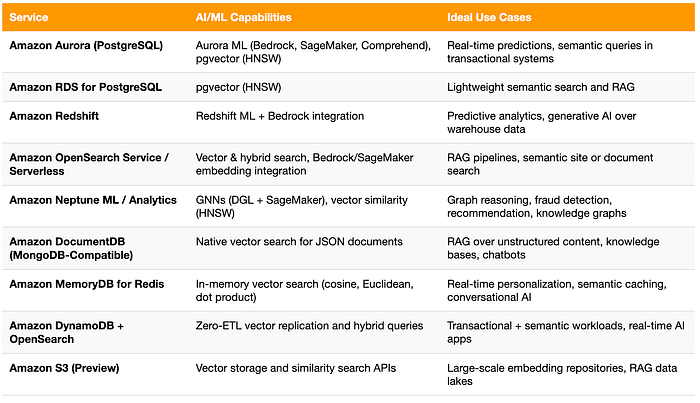
Comparison of AI/ML Capabilities Across AWS Databases
With so many AWS databases now supporting AI and vector capabilities, it helps to see how they fit together. The table below summarizes the key AI/ML features and ideal use cases across each service, from transactional intelligence in Aurora to large-scale embedding storage in S3.
Future Outlook: The Convergence of Data and Intelligence
AWS continues to blur the boundaries between databases, analytics, and AI. Expect deeper Bedrock integrations across Aurora, Redshift, and OpenSearch, as well as native vector capabilities extending to services like DynamoDB and S3.
In the near future, AI-ready databases will not just store information but continuously learn from it, optimizing queries, predicting trends, and adapting to workload patterns automatically. This convergence marks the next step in the evolution of cloud databases, where data and intelligence live side by side.
AI-ready databases are no longer a vision. They’re the new reality on AWS. From Aurora ML and pgvector to Redshift ML, OpenSearch, Neptune ML, DocumentDB, and MemoryDB, AWS now provides a unified foundation for building intelligent, data-driven applications.
Adopting these capabilities can transform your data stack into a true intelligence layer, powering predictive insights, semantic search, and real-time decision-making directly where your data lives.
If you’re exploring how to make your database architecture AI-ready or planning a proof of concept on AWS, DoiT can help. Our team of over 100 senior cloud architects and data specialists partners with organizations worldwide to modernize infrastructure, optimize performance, and unlock the full potential of cloud-native AI systems.