

If you’re trying to get a grip on anomaly detection with machine learning, you’re not alone. Maybe you spent hours figuring out why cloud costs spiked last month—or you’re struggling to tell the difference between normal traffic surges and potential security threats.
Unanticipated patterns in cloud environments can drain operational efficiency and cost thousands if they aren’t addressed quickly. Anomalies show up in multiple ways: sudden increases in cloud spend, irregular system behavior that hurts performance, or suspicious activity that puts sensitive data at risk.
Cloud complexity adds another layer of difficulty. Multiple services and dependencies can make it hard to pinpoint root cause. To keep systems reliable and reduce risk, teams need a way to detect and respond to outliers quickly and accurately.
This guide explains what anomaly detection is, the main anomaly types to watch for, common machine learning techniques and algorithms, and practical implementation best practices.
What is anomaly detection?
 Source: DoiT Anomaly Detection
Source: DoiT Anomaly Detection
At its core, anomaly detection identifies patterns that don’t match expected behavior. In cloud environments, it acts like an immune system: constantly monitoring, learning what “normal” looks like, and flagging meaningful deviations.
Cloud anomalies typically surface in two areas:
- Operational anomalies: changes in performance, reliability, or system behavior (latency spikes, error-rate changes, unusual access patterns).
- Cost anomalies: unexpected increases in spend that may or may not correlate to traffic or performance changes.
These often overlap (a traffic surge can raise both spend and latency), but cost anomalies can also happen without obvious operational symptoms—like a logging misconfiguration, an accidental feature flag, or a pricing/usage shift.
Modern anomaly detection systems avoid relying only on static thresholds. Instead, they use machine learning to adapt to dynamic baselines that change by hour, day, or season. For example, an ecommerce platform’s traffic spike during an annual sale is expected—yet the same spike on a random weekday might indicate a bot attack or a broken deployment.
Types of anomalies to watch for
In cloud environments, anomalies commonly fall into security, operations, and cost categories. Across those, anomalies tend to appear in three pattern types:
Point anomalies
A single data point that is dramatically different from the rest—like a 10x spike in API calls or a sudden surge in data transfer costs. These can be easy to spot, but the hard part is determining whether they’re legitimate (a product launch) or suspicious (credential misuse).
Contextual anomalies
Behavior that’s only anomalous in a specific context—like high CPU being normal during peak hours but concerning at 3 a.m. These require models that understand time, seasonality, and business cycles.
Collective anomalies
A set of events that looks normal individually but becomes suspicious when viewed together—like coordinated requests that reveal a DDoS pattern or a slow-burn cost creep spread across multiple services.
3 anomaly detection techniques to spot issues early
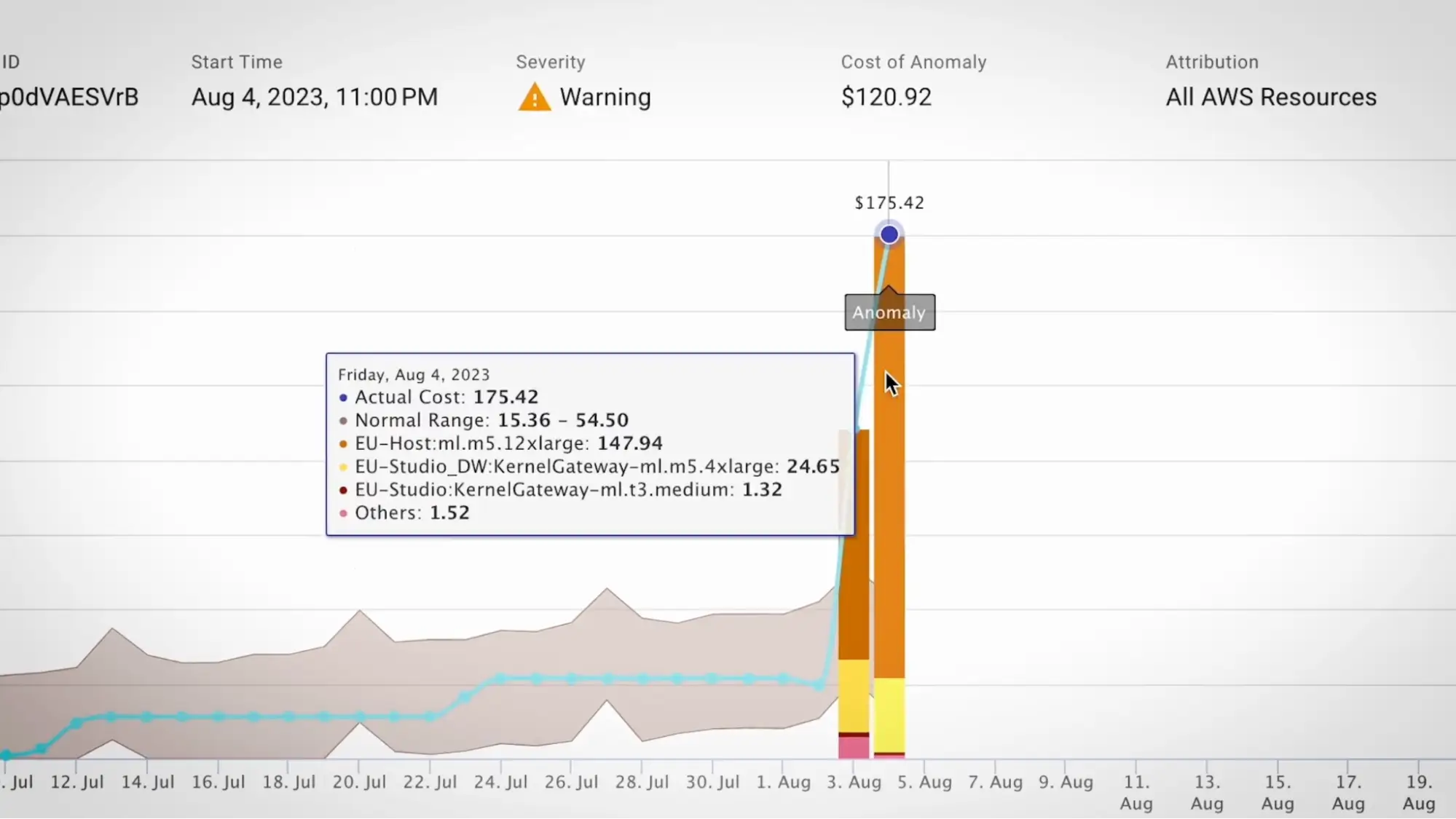 Source: FinOps tools guide
Source: FinOps tools guide
Different anomaly detection techniques work best in different environments. In practice, cloud teams choose based on data availability, how fast systems change, and the types of anomalies they need to catch.
1) Supervised detection
Supervised detection trains models using labeled examples of normal behavior and known anomalies. It can be highly accurate for familiar issues, but it struggles with new or rare events you don’t have examples for.
2) Unsupervised detection
Unsupervised detection is often the default for cloud environments because it doesn’t require labeled anomaly data. It learns what “normal” looks like by observing patterns over time, then flags events that are rare or meaningfully different.
This approach is especially useful when systems are new (no labeled history) or constantly changing. As your environment evolves, unsupervised methods can continue adapting to new baselines.
3) Semi-supervised detection
Semi-supervised detection uses a small amount of labeled data to improve accuracy while remaining flexible enough to detect previously unseen issues. It’s often used when you have reliable examples of “normal” but limited anomaly labels.
In reality, many cloud anomaly systems lean heavily on unsupervised methods because waiting to collect and label enough anomalies isn’t practical. The best systems start protecting immediately and keep learning as patterns change.
Common algorithms for anomaly detection
Anomaly detection systems use a range of statistical, machine learning, and deep learning approaches—each suited to different data shapes and operational needs.
Statistical and rules-based methods
Methods like Z-score analysis, interquartile range (IQR), and simple thresholding can work well for clear deviations in stable datasets. They’re fast and easy to implement, which makes them useful for real-time detection in straightforward distributions.
Machine learning methods
For more complex data, ML approaches add pattern recognition. Tree-based methods (including isolation forests) are commonly used because anomalies tend to be rare and easier to isolate than normal points, making them efficient for large datasets.
Deep learning methods
Deep learning approaches—especially autoencoders—excel in high-dimensional data where “normal” behavior is complex. They learn a compressed representation of normal patterns and flag deviations when reconstruction error is high.
Time-series forecasting methods
When data is time-dependent, forecasting helps define expected ranges. ARIMA and Prophet are often used for seasonal patterns and irregular trends. These approaches help detect anomalies by comparing actual values against predicted baselines.
Real-world applications of anomaly detection
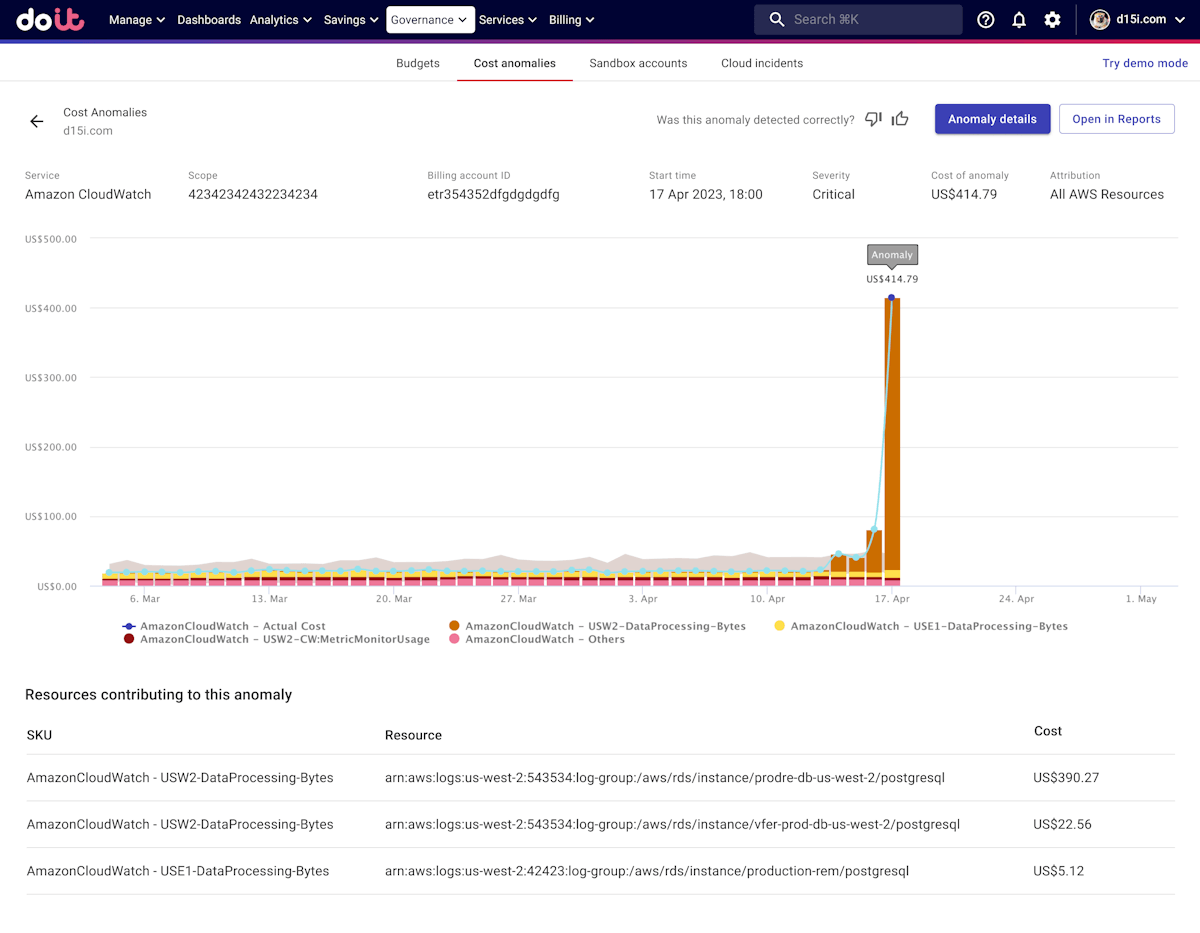 Source: DoiT changelog
Source: DoiT changelog
Anomaly detection in cloud environments goes beyond basic monitoring. Common applications include:
Cloud cost management
In cloud cost management, anomaly detection identifies unusual spending patterns early so teams can investigate and remediate before the month-end bill lands. For example, Moralis partnered with DoiT and realized 10% cost savings after implementation. A proactive approach can also help reduce cloud bill surprises.
Infrastructure monitoring
In infrastructure monitoring, anomaly detection can identify subtle deviations in performance metrics and help predict issues before they become outages—shifting operations from reactive firefighting to proactive prevention.
Security monitoring
Security teams use anomaly detection to surface unusual access patterns, suspicious behavior, and potential breaches—especially when attacks attempt to blend in with “normal-looking” activity.
Challenges in anomaly detection
Anomaly detection can deliver major value, but real-world implementations run into predictable hurdles. Knowing them upfront helps teams avoid common failure modes.
The data-quality dilemma
Reliable baselines require enough clean, relevant data. Poor quality or incomplete data makes it harder to distinguish normal variation from true anomalies—leading to inaccurate alerts.
The false-positive problem
Many systems struggle with false positives. Too many alerts create fatigue, and teams start ignoring notifications—raising the risk of missing real issues. Sensitivity tuning and context-aware baselines are essential.
The cost factor
Processing large volumes of data (billing, logs, metrics) and training models can be compute-intensive. For many organizations, running this in-house adds overhead and operational complexity.
Cloud environment complexity
Cloud usage patterns change frequently. Services are interdependent, and resource consumption varies with demand. Baselines must continuously adapt without becoming so loose they miss real anomalies.
Integration and workflow alignment
Detection only matters if it fits how teams work. Alerts need to route to the right owners, include actionable context, and integrate with incident and FinOps workflows. Without alignment and training, even strong detection systems underperform.
Best practices for implementing anomaly detection
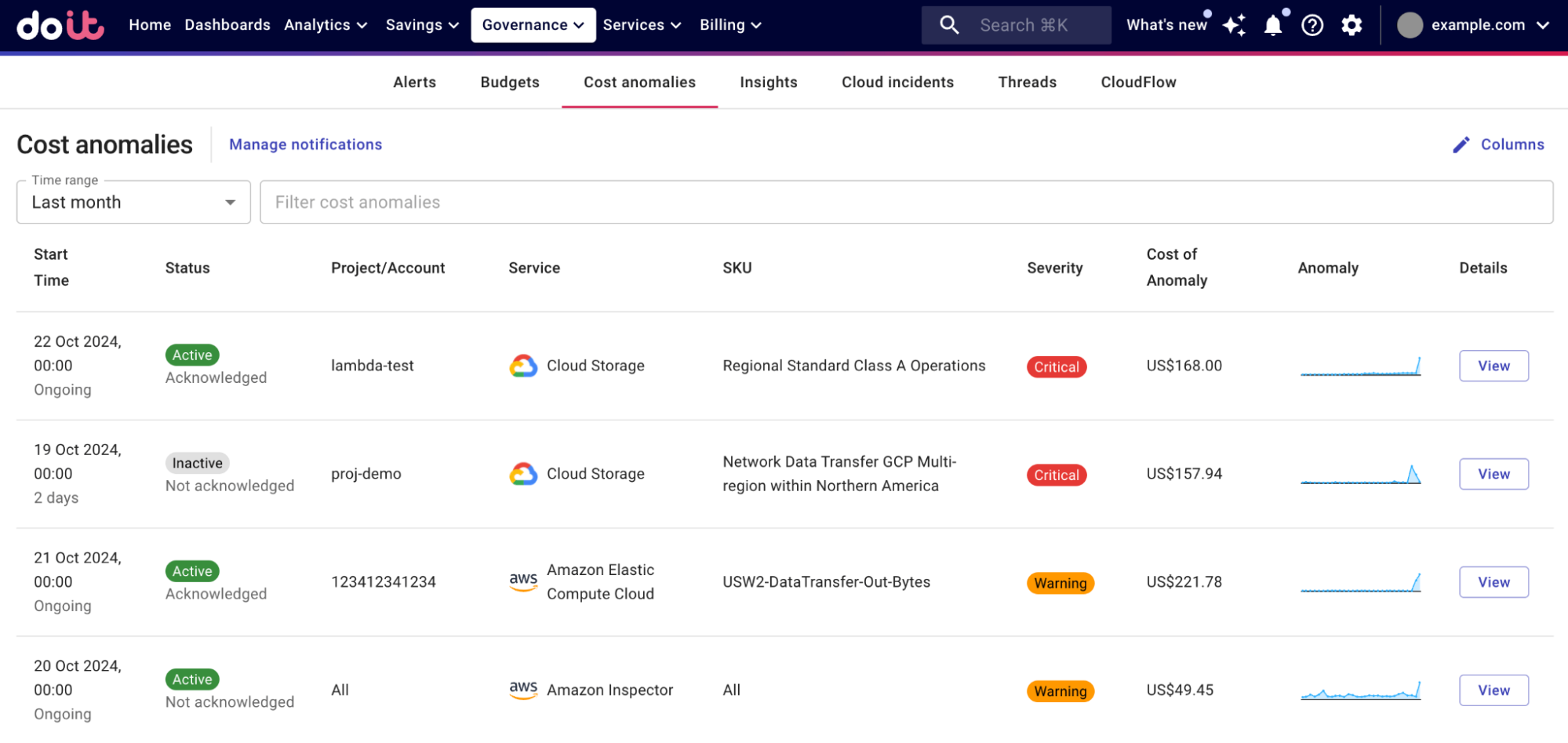 Source: DoiT Help Center
Source: DoiT Help Center
Define what “anomaly” means for your environment
Start with clear objectives. Decide which anomalies matter (cost, reliability, security) and define success metrics such as detection speed, false-positive rate, and time-to-triage.
Prioritize actionable alerts over more alerts
Design alerts around workflows. Severity should map to response: who gets notified, how quickly, and what steps they take next.
Plan response mechanisms in advance
Detection is only step one. Build response capabilities, such as:
- Dynamic thresholds that adapt to baselines.
- Automated remediation for low-risk fixes.
- Scaling guardrails to prevent runaway usage.
- Notification routing based on severity and ownership.
Continuously tune the system
Cloud environments evolve; anomaly detection must evolve with them. Retrain models, refine baselines, adjust thresholds, and track performance over time to maintain signal quality.
Document escalation paths and automate repeatable actions
Create clear playbooks for common anomaly types. Automate safe, repeatable responses so the team spends time on investigation and root cause—not manual busywork.
FAQ: Anomaly detection with machine learning
What is anomaly detection in machine learning?
Anomaly detection is a method for identifying data points or patterns that deviate significantly from expected behavior. In machine learning, it often uses models that learn normal behavior from historical patterns and flag rare or unusual events.
What’s the difference between supervised and unsupervised anomaly detection?
Supervised detection learns from labeled examples of normal and anomalous behavior. Unsupervised detection does not require labels; it learns normal patterns from data and flags outliers. In cloud environments, unsupervised is common because labeled anomalies are rare.
Why is anomaly detection important for cloud cost management?
Anomaly detection can spot unexpected spending changes early—before a monthly invoice arrives—so teams can investigate misconfigurations, unexpected usage, or waste and reduce budget surprises.
How do you reduce false positives in anomaly detection?
Use context-aware baselines (time of day, day of week, seasonality), tune sensitivity thresholds, and route alerts based on severity and ownership. Pairing alerts with root-cause context also reduces noise.
Making cloud spend more predictable with DoiT
Anomaly Detection in DoiT Cloud Intelligence monitors cloud spend and flags unusual patterns so you can investigate before surprises hit your budget.
Our approach combines machine learning with cloud expertise to deliver actionable alerts tailored to your environment. Learn how DoiT supports more precise anomaly detection aligned to your usage patterns and operational needs.
If you want to explore the platform, you can review DoiT’s product and pricing options to make cloud spend more predictable and cost-efficient.