
Introduction
ARM chips have been the go-to choice for mobile phones and small gadgets since Apple Newton came out in 1993, powering most smartphones we use today. Recently, these chips have entered a new field: cloud computing, with Amazon’s AWS Graviton in 2018 being the first ARM processor designed by a major cloud company.
The foundry model, a successful business model for designing and manufacturing integrated circuits, was adapted to create cloud ARM server CPUs. Here is how it is generally implemented
- ARM Holdings designs SIP Cores based on RISC architecture and licenses them to other companies.
- Hyperscalers (Amazon, Google, and Azure), who also happened to be fabless semiconductor manufacturers, implement those SIP cores, add additional customization, and create tape-out s for CPUs.
- These tape-outs are then sent to a pure-play semiconductor foundry for actual device fabrication.
ARM’s Neoverse series is a family of CPUs specifically designed for cloud computing, HPC, and AI workloads.
In this blog post, we will benchmark two implementations of the Neoverse V2 architecture: AWS Graviton 4 and Google Axion. We have excluded Azure Cobalt 100 from this comparison as it utilizes a slightly different variant of the Neoverse architecture: Neoverse N.
The Test Suite
Web applications are among the most frequently deployed cloud workloads. To assess the performance of Graviton 4 and Axion CPUs for web application workloads, we will leverage the TechEmpower Framework Benchmarks(TFB). It provides tests for various programming languages and frameworks, but for simplicity, we will use the famous JVM-based reactive application framework, Vert.x
TFB tests evaluate web frameworks’ performance in areas like request routing, JSON handling, throughput, and database interactions (ORM mapping, caching, and connection pooling). TFB requires three virtual machines to conduct these tests: an application server for deploying the web framework, a database server, and a load generator..
Infrastructure Setup
For AWS, we used 3 R8g.xlarge (4 vCPU, 32 Gib Memory ) and 20 GB (gp3 SSD) VMs. All these VMs were deployed in a single AZ to minimize cross-AZ network latency.
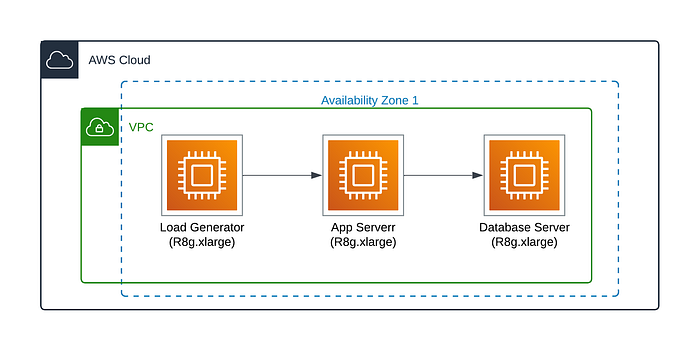
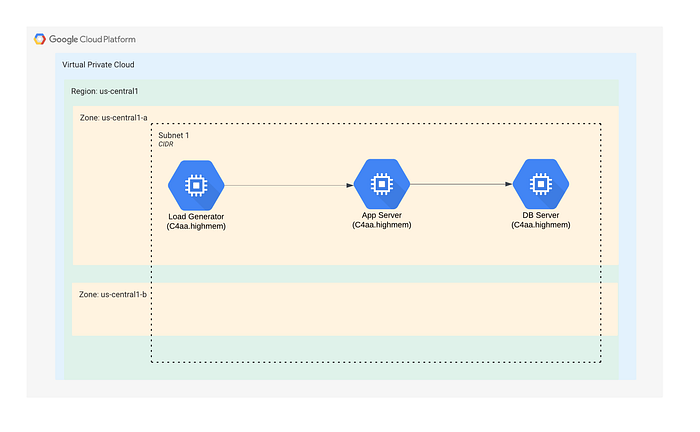
Similarly, we used C4A-highmem-4 (4 vCPU, 32 Gib Memory) and 20 GB SSD for GCP. All VMs are deployed on a single AZ.
Benchmark results
(TFB) employ a powerful tool called wrk to simulate real-world loads on application servers. Here’s how it works:
- wrk creates varying levels of concurrent requests, mimicking different user traffic intensities.
- The benchmark tracks the number of rows returned for each test scenario.
- A higher row count indicates superior CPU performance, demonstrating the processor’s ability to handle more data under pressure.
Here are the results for each of the test cases (higher is better)
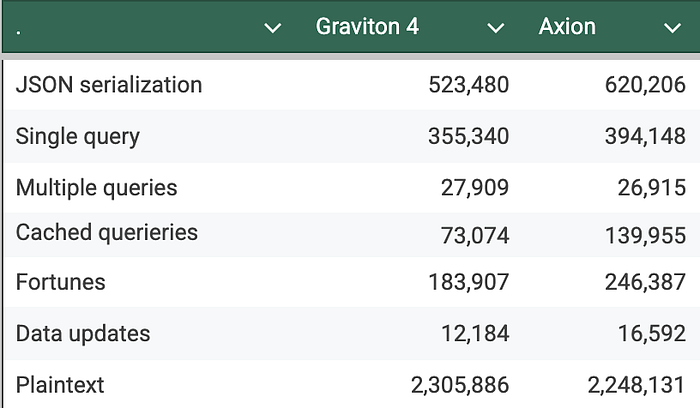
Higher number indicates superior performance, demonstrating the processor’s ability to handle more data under pressure (higher is better)
The following graph plots these numbers on a bar chart. It highlights the percentage difference in performance between Graviton 4 and Axion.
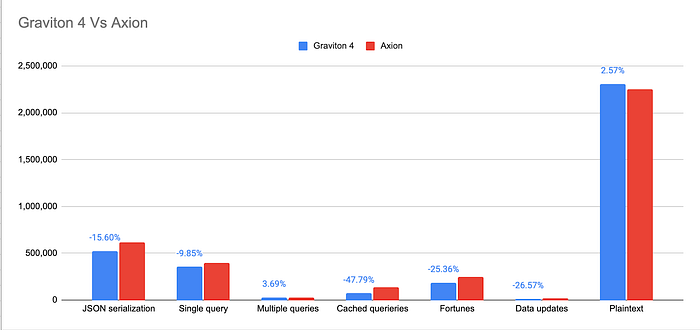
Graph highlights the percentage difference in performance between Graviton 4 and Axion. (Higher is better)
Conclusion
It is clear from these results that GCP’s latest ARM-based chip, Axion, outperforms AWS Graviton in 5 out of 7 test cases. Axion’s advantage ranges from a notable 9.85% to an impressive 47.79% improvement over Graviton 4. In only two test cases (plaintext and multiple queries) does Graviton demonstrate superior performance, outpacing Axion by 2.57 and 3.69%. Further investigation is needed to determine the optimal chip choice based on specific application requirements and cost considerations.
Reach out to us at DoiT . Staffed exclusively with senior engineering talent, we specialize in providing advanced cloud consulting architectural design, debugging advice, and consulting services.