
A strategic perspective on implementing real-time voice-first AI in the generative era

The Next Frontier: Why Voice, Why Now?
Conversational AI has reached an inflection point. Voice is no longer a novelty. It is the most human, efficient, and emotionally intelligent way for enterprises to connect with customers, employees, and partners. Today, speech-to-speech generative AI finally makes these voice-first experiences practical, scalable, and cost-effective. The moment for change is now.
Why Now?
Why is this happening today? Several key shifts are converging:
- Unified speech-to-speech large language models, like Amazon Nova Sonic, collapse speech recognition, reasoning, and speech generation into a single, real-time architecture
- Latency is dramatically reduced while conversation quality improves
- Customers and employees expect seamless, voice-based interactions more than ever
The combination of mature generative technology and rising expectations is redefining what’s possible — and what’s competitive.
What Is a Voice AI Assistant?
A voice AI assistant is a conversational agent that can listen, reason, and respond in natural spoken language, managing complex, multi-turn dialogues in real time. Designed with enterprise-grade security and governance in mind, these assistants are a far cry from traditional scripted bots.
They are capable of:
- Responding fluidly without robotic pauses
- Mirroring emotion and tone
- Understanding nuanced user intent
- Integrating with enterprise knowledge and performing actions
That makes them perfect for use cases such as HR interviewing, customer service, proactive sales calls, or employee coaching.
The Business Value of Voice Generative AI
For senior leaders evaluating voice AI, the business case is compelling:
- Reduce operational costs by automating routine voice interactions
- Improve customer satisfaction through more natural, empathetic conversations
- Serve users around the clock, across languages and geographies
- Enable new revenue streams through proactive, voice-based outreach
- Empower employees with instant, on-demand voice knowledge assistants
Voice is the channel people prefer. Generative AI finally makes it scalable, secure, and consistent.
From STT→LLM→TTS to Unified Speech-to-Speech: A Paradigm Shift
Traditionally, voice AI systems have been built using a cascaded pipeline of separate components. This pipeline is often represented as STT→LLM→TTS, which stands for Speech-to-Text→Large Language Model→Text-to-Speech. In a typical voice assistant or call bot, spoken input goes through the following steps:
- Automatic Speech Recognition (ASR): The user’s speech is converted to text using a speech-to-text model (e.g., Amazon Transcribe or Google Speech API).
- Language Understanding / LLM Processing: The transcribed text is passed into a language model or dialogue manager (such as an LLM), which generates a text response based on the user’s query and context.
- Text-to-Speech (TTS) Synthesis: The AI’s text reply is then converted into spoken audio using a voice synthesis engine (e.g., Amazon Polly or Google’s WaveNet).
- Audio Playback: The synthesized speech is played back to the user as the answer.
Each of these steps often involved distinct models or services, and they had to be orchestrated in sequence. The Pipecat open-source framework from Daily (used in AWS reference architectures) exemplifies this pipeline approach: it integrates WebRTC for audio streaming, a voice activity detector (to detect when the user is speaking), Amazon Transcribe for ASR, an LLM (Amazon Nova text model) for NLU/NLG, and Amazon Polly for TTS. Figure 1 below illustrates such a cascaded voice AI architecture in an enterprise setting, where multiple AWS services work in concert to handle a single user query end-to-end.
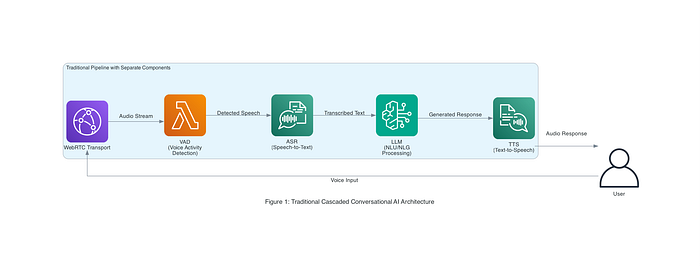
Figure 1: A traditional cascaded Conversational AI architecture (from AWS Pipecat reference). Voice input travels through WebRTC transport, VAD (voice activity detection), ASR (speech-to-text), an LLM for NLU/NLG, and TTS for the response. Each component adds processing time and potential points of failure.
While this modular pipeline has the advantage of leveraging specialized components for each task, it also comes with drawbacks. The hand-off between services introduces latency — users must often finish speaking before the AI starts formulating a response, leading to noticeable pauses. Each component can also introduce errors (e.g., transcription mistakes or robotic-sounding TTS output), which may compound and reduce the overall conversational quality. Maintaining conversational coherence can be challenging when the ASR and TTS are unaware of each other’s nuances or the conversation’s emotional tone. In short, the interactions can feel less natural due to system delays and the mismatch of disjointed parts.
Amazon Nova Sonic: A Technology Breakthrough
Amazon’s Nova Sonic is a major leap forward. Instead of gluing together separate speech-to-text, reasoning, and text-to-speech components, Nova Sonic unifies the entire conversational process into a single, streamlined, and secure pipeline.
At a glance, Nova Sonic can:
- Listen and understand in real time
- Generate human-like responses
- Speak with expressive, adaptive voices
- Perform function calls to take action
- Ground answers in enterprise knowledge
It is delivered as an API through Bedrock, so there is no need to host or train models yourself. This simplicity removes barriers to production adoption, even in regulated or security-sensitive environments.
From Vision to Execution: How DoiT Helps
At DoiT International, we believe every successful voice AI initiative depends on three essential pillars:
✅ Natural conversation powered by Nova Sonic’s unified speech-to-speech capabilities
✅ Real-time infrastructure built on secure WebRTC, streaming, and containerised microservices
✅ Enterprise-grade controls for compliance, governance, and monitoring
Our team helps organizations put these pillars into practice with a well-architected framework that translates research into secure, scalable, real-world deployments.
How it comes together:
The reference blueprint brings together a secure WebRTC front end, containerized microservices on AWS Fargate, and a Bedrock-managed Nova Sonic backend for real-time, voice-to-voice conversation. Role-based IAM, secure secrets, CloudFront distribution, and comprehensive observability complete the design, ensuring confidence at scale.
For more information, please visit our reference GitHub repository. Please note that this repository is intended for evaluation and testing purposes only and is not yet suitable for production deployment

Figure 1: High-level architecture diagram showing the complete system integration between frontend components, backend services, and AWS cloud resources.
AWS Architecture Components
The Nova Sonic implementation utilizes several key AWS services:
- Nova Sonic Service ✅ Core speech-to-speech AI capabilities
✅ Real-time audio processing
✅ Streaming response generation
✅ Voice customization options 2. Amazon Bedrock ✅ Foundation model integration
✅ Context-aware response generation
✅ Function calling capabilities
✅ Knowledge management 3. Container Services ✅ ECS Fargate for containerised backend services
✅ Auto-scaling based on demand
✅ Resource optimization
✅ Deployment automation 4. Supporting Services ✅ CloudFront for global content delivery
✅ DynamoDB for state management
✅ S3 for recording storage
✅ CloudWatch for observability
Key Integration Points
The architecture is built around several critical integration points:
- Frontend-Backend Integration ✅ WebRTC signaling via FastAPI endpoints
✅ Secure room credential exchange
✅ Media stream initialization
✅ Connection state synchronization 2. Backend-AWS Integration ✅ Secure AWS service authentication
✅ Streaming connections to Nova Sonic
✅ State synchronization with DynamoDB
✅ Monitoring integration with CloudWatch 3. Pipeline Component Integration ✅ Standardized frame interfaces
✅ Event-driven communication
✅ Bidirectional data flow
✅ Modular component architecture
Security and Scaling Considerations
The implementation incorporates enterprise-grade security and scaling features:
- Security Measures ✅ Token-based room authentication
✅ Encrypted media transmission
✅ Secure credential management
✅ Role-based access control 2. Scaling Strategy ✅ Horizontal scaling of backend services
✅ Connection pooling for efficient resource use
✅ Regional deployment for global coverage
✅ Auto-scaling based on connection metrics 3. Resilience Features ✅ Automatic reconnection handling
✅ Graceful degradation during service disruptions
✅ Comprehensive error handling
✅ Session recovery mechanisms
This architecture provides a blueprint for organizations seeking to implement Nova Sonic in enterprise environments, with particular attention to security, scalability, and integration with existing systems.
Voice Processing Pipeline Architecture
Amazon Nova Sonic’s breakthrough capability is built on an advanced voice processing pipeline that enables near real-time speech-to-speech interactions. Unlike traditional voice assistants that process complete utterances before responding, Nova Sonic continuously processes audio streams bidirectionally, enabling natural conversation flow with minimal latency.
The voice processing pipeline consists of the following key components:
- Audio Capture and Streaming Layer ✅ WebRTC protocol for real-time audio transmission
✅ Browser-based audio processing with echo cancellation and noise reduction
✅ Adaptive bitrate encoding based on network conditions 2. Speech Recognition Component ✅ Continuous streaming ASR (Automatic Speech Recognition)
✅ Low-latency phoneme-level recognition
✅ Context-aware language modeling for improved accuracy 3. Semantic Processing Engine ✅ Real-time intent detection while user is speaking
✅ Multi-turn context management for conversation coherence
✅ Query formulation and optimization for LLM interaction 4. Nova Sonic Generative AI Backend ✅ Streaming token generation with minimal buffering
✅ Neural speech synthesis with voice customization
✅ Prosody and tone control for natural speech output 5. Output Generation and Mixing ✅ Dynamic audio mixing for seamless conversation
✅ Latency optimization techniques
✅ Real-time feedback loop for audio quality control
WebRTC Communication Flow
The WebRTC implementation enables secure, low-latency bidirectional audio streams between the client application and the Nova Sonic service:
- Session Establishment ✅ ICE (Interactive Connectivity Establishment) protocol identifies optimal network paths
✅ STUN/TURN servers facilitate NAT traversal
✅ SDP (Session Description Protocol) negotiates media capabilities 2. Secure Media Transmission ✅ DTLS (Datagram Transport Layer Security) provides encryption
✅ SRTP (Secure Real-time Transport Protocol) ensures secure audio streaming
✅ Bandwidth adaptation based on network conditions 3. Audio Processing ✅ Client-side audio processing (echo cancellation, noise suppression)
✅ Server-side audio enhancement
✅ Packet loss concealment techniques
AWS Architecture and Function Orchestration
The implementation leverages several AWS services in a scalable, resilient architecture:
- Client-Facing Components ✅ CloudFront distribution for global content delivery
✅ Application Load Balancer for traffic distribution
✅ ECS Fargate for containerized application hosting 2. Processing Pipeline ✅ Amazon Bedrock for generative AI capabilities
✅ Amazon Transcribe for speech recognition
✅ Amazon Polly for speech synthesis
✅ Custom Lambda functions for orchestration 3. Backend Services ✅ DynamoDB for session management and metadata
✅ Parameter Store for secure credential management
✅ CloudWatch for comprehensive logging and monitoring 4. Security Layer ✅ ACM certificates for TLS encryption
✅ IAM roles for fine-grained access control
✅ AWS WAF for web application firewall protection
The AWS implementation utilises infrastructure as code (IaC) through AWS CDK, enabling reproducible deployments and consistent environments. The architecture follows AWS Well-Architected Framework principles for security, reliability, performance efficiency, cost optimization, and operational excellence.
Performance Optimization
Nova Sonic’s low-latency performance is achieved through several technical optimizations:
- Streaming Inference Optimization ✅ Parallel processing of audio chunks
✅ Adaptive buffering strategies
✅ Early response generation based on partial inputs 2. Network Latency Reduction ✅ Edge computing deployment model
✅ Connection pooling for backend services
✅ Regional deployment for proximity to end-users 3. Resource Scaling ✅ Auto-scaling ECS services based on demand
✅ Reserved capacity for consistent performance
✅ Workload distribution across availability zones
Frontend Components Implementation
The frontend implementation of Nova Sonic demonstrates how modern web technologies can enable real-time voice interactions with minimal latency. The implementation in the /vite-client directory showcases a production-ready approach to building voice AI interfaces that feel natural and responsive.
WebRTC Client Implementation
The client-side WebRTC implementation is encapsulated in the ChatbotClient class within app.js, which handles the connection lifecycle and media management:
class ChatbotClient {
constructor() {
// Initialize client state
this.rtviClient = null;
this.videoManager = null;
this.setupDOMElements();
this.setupEventListeners();
this.initializeClientAndTransport();
}
// ...
}
The implementation leverages specialized libraries:
@pipecat-ai/client-js: Provides theRTVIClientclass for real-time voice interactions@pipecat-ai/daily-transport: Enables WebRTC communication through Daily.co infrastructure. The first 10,000 participant minutes is free.
Key features of the WebRTC implementation include:
- Transport Layer Abstraction ✅ Encapsulation of WebRTC complexity through a transport interface
✅ Automatic handling of ICE candidate negotiation
✅ Seamless reconnection strategies for network disruptions 2. Media Stream Management ✅ Dynamic track subscription and unsubscription
✅ Automatic media format negotiation
✅ Optimized media quality based on bandwidth conditions 3. Connection State Management ✅ Robust state transitions (connecting, connected, disconnected)
✅ Event-driven architecture for responsive UI updates
✅ Comprehensive error handling for connection failures
Microphone and Camera Handling Components
The project implements sophisticated media device management through the VideoManager class, which provides:
- Device Initialization and Permission Flow ✅ User-friendly camera permission requests
✅ Detailed error handling for permission denials
✅ Visual feedback during device initialization 2. Media Track Management ✅ Separate handling of local and remote media tracks
✅ Quality optimization for video streams
✅ Automatic track cleanup on disconnection 3. Media Element Integration ✅ Dynamic creation and configuration of audio/video elements
✅ Responsive layout adaptation
✅ Optimized playback settings for low latency
This example from VideoManager.js demonstrates how camera streams are initialised:
async toggleLocalCamera() {
try {
// Request camera access through the browser
const stream = await navigator.mediaDevices.getUserMedia({
video: {
width: { ideal: 1280 },
height: { ideal: 720 }
}
});
// Store the stream for later use
this._localStream = stream;
// Update the local video element with this stream
this.localVideo.srcObject = stream;
// Ensure the video plays
await this.localVideo.play();
} catch (error) {
// Handle permission errors with user-friendly messaging
}
}
User Interface for Voice Interaction
The user interface is designed for intuitive voice interaction with the following features:
- Connection Controls ✅ Clear visual indicators of connection state
✅ One-click connect/disconnect functionality
✅ Permissions management interface 2. Visual Feedback ✅ Real-time transcription display
✅ Animated visual indicators during bot speech
✅ Connection status indicators 3. Debug Capabilities ✅ Comprehensive logging interface
✅ Network statistics monitoring
✅ Audio level visualization
Key Frontend Technologies and Libraries
The frontend implementation leverages several modern web technologies:
- Vite — For fast development and optimised production builds
- WebRTC APIs — For real-time audio/video communication
- Media Streams API — For accessing device cameras and microphones
- Containerization — Docker configuration for consistent deployment
- Nginx — For static file serving and optional proxying
Connection Management with Backend
The frontend-backend connection is managed through a robust protocol that:
- Establishes secure room-based connections ✅ Obtains room credentials from the backend
/connectendpoint
✅ Secures connections with tokens
✅ Handles participant events (joining, leaving) 2. Manages media transmission efficiently ✅ Implements bandwidth adaptation
✅ Handles network transitions
✅ Provides quality metrics and diagnostics 3. Optimizes for low-latency voice interaction ✅ Configures audio elements for minimal processing delay
✅ Implements audio buffering optimization
✅ Uses hardware acceleration when available
This architecture enables the critical sub-300ms latency that makes Nova Sonic conversations feel natural and fluid.
Backend Components Implementation
The server-side implementation in the /server directory showcases how to build a scalable, production-ready backend for Nova Sonic voice AI applications. This implementation demonstrates the integration patterns and architectural decisions required to deploy enterprise-grade voice AI solutions.
WebRTC using Daily Transport Implementation
The backend leverages Daily.co’s infrastructure for WebRTC session management through a specialized transport implementation:
# Set up Daily transport with video/audio parameters
transport = DailyTransport(
room_url,
token,
"Chatbot",
DailyParams(
audio_in_enabled=True,
audio_out_enabled=True,
video_in_enabled=True,
video_out_enabled=True,
video_out_width=1024,
video_out_height=576,
vad_analyzer=SileroVADAnalyzer(),
transcription_enabled=True,
),
)
Key features of the transport implementation include:
- Room Management ✅ Dynamic creation of secure rooms
✅ Token-based authentication
✅ Automatic cleanup of unused resources 2. Media Configuration ✅ Independent control of audio/video input and output
✅ Resolution and quality settings
✅ Voice Activity Detection (VAD) integration 3. Event Handling ✅ Comprehensive event system for transport state changes
✅ Participant lifecycle management
✅ Recording control and management
Function Call Patterns for Tool Integration
The implementation demonstrates advanced function calling patterns that enable tool integration with the LLM:
# Register functions with the LLM service
register_functions(llm)
# Set up context with function schemas
context = OpenAILLMContext(
messages=[\
{"role": "system", "content": f"{system_instruction}"},\
{\
"role": "user",\
"content": "Hello, I'm here for my interview.",\
},\
],
tools=function_tools_schema,
)
This architecture enables:
- Tool Registration System ✅ Dynamic registration of function schemas
✅ Type-safe function interfaces
✅ Support for synchronous and asynchronous functions 2. Context Management ✅ Preservation of conversation context across interactions
✅ Efficient context windowing for long conversations
✅ Stateful conversation tracking 3. Function Execution ✅ Secure execution of tool functions
✅ Error handling and retry mechanisms
✅ Result incorporation into the conversation context
Pipeline Architecture and Components
The backend implements a sophisticated pipeline architecture using the Pipecat framework:
pipeline = Pipeline(
[\
transport.input(),\
rtvi,\
context_aggregator.user(),\
llm,\
ta,\
transport.output(),\
context_aggregator.assistant(),\
]
)
This pipeline approach provides:
- Modular Processing Chain ✅ Clear separation of responsibilities
✅ Pluggable components for customization
✅ Standardized frame processing interfaces 2. Bidirectional Data Flow ✅ Input processing from user to system
✅ Output processing from system to user
✅ Event propagation in both directions 3. Observability Integration ✅ Pipeline-level metrics collection
✅ Component-level diagnostics
✅ Performance monitoring points
Audio Processing and Handling
The implementation includes sophisticated audio processing capabilities:
- Voice Activity Detection ✅ ML-based voice activity detection using Silero VAD
✅ Dynamic threshold adjustment
✅ Noise-resilient speech detection 2. Transcription Management ✅ Real-time speech-to-text conversion
✅ Partial results handling for immediate feedback
✅ Final transcript synchronization 3. Audio Output Optimization ✅ Dynamic mixing of audio streams
✅ Latency management techniques
✅ Playback synchronization
Integration with AWS Nova Sonic Services
The heart of the implementation is the integration with AWS Nova Sonic services:
# Initialize AWS Nova Sonic LLM service
llm = AWSNovaSonicLLMService(
secret_access_key=NOVA_AWS_SECRET_ACCESS_KEY,
access_key_id=NOVA_AWS_ACCESS_KEY_ID,
region=os.getenv("NOVA_AWS_REGION", "us-east-1"),
voice_id=os.getenv("NOVA_VOICE_ID", "tiffany"),
send_transcription_frames=True
)
This integration showcases:
- Secure Authentication ✅ AWS credential management
✅ Role-based access control
✅ Secure environment variable handling 2. Voice Customization ✅ Voice selection and configuration
✅ Prosody and speech characteristics
✅ Multilingual support options 3. Streaming Optimization ✅ Real-time token streaming
✅ Progressive response generation
✅ Minimal latency configuration 4. Advanced Features ✅ Transcription frame integration
✅ Context-aware responses
✅ Interruption handling
Executive Action Plan for Voice Generative AI
Here is a practical playbook to get started:
- Identify which customer or employee experiences could benefit most from faster, more natural voice interactions
- Build a business case focused on cost, experience, or revenue upside
- Evaluate partners who can deliver the right mix of cloud, AI, and security expertise
- Pilot and measure results with clear success criteria
- Put governance and security controls in place for scale
- Roll out in phases, using infrastructure-as-code and proven observability patterns
Looking Ahead
Voice is the most natural interface we have. Thanks to generative AI, it can now be as scalable, secure, and intelligent as text-based systems. The future of customer and employee engagement will be built on voice-first, human-like conversations.
For forward-thinking organizations, the moment to invest is right now.
At DoiT International, we combine deep cloud, security, and generative AI expertise to help you make voice-first solutions a success, reliably and at scale.
Let’s build the next generation of conversational AI together. Reach out to DoiT International today!