
With the growing popularity of event-driven architecture, some of Google Pub/Sub’s missing features may require building certain workarounds. We thought we’d share our approach for Deduplication, Delayed Messaging and FIFO solutions using Google Cloud-native services.
This was co-written with Moshe Ohaion .

Introduction
The event-driven architecture is so popular these days that I’m sure I’ve heard my grandma talk about it the other night at dinner. So many systems’ architectures utilize messaging services either as messaging-oriented middleware or event ingestion and delivery for streaming analytics pipelines. When working on GCP (Google Cloud Platform) you can take advantage of the managed service Google Pub/Sub as event ingestion and delivery system.
While Google Pub/Sub promises critical features like durable message storage, real-time message delivery with high availability, consistent performance at scale, and at-least-once delivery, as with each messaging service it also has several missing features which could be critical for choosing different alternatives.
In this article, we’d like to share with you some easy ways to overcome three of these “dealbreakers” and still stay with GCP Pub/Sub native choice.
Deduplication
Pub/Sub guarantees at-least-once (but not exactly once) message delivery, which means that occasional duplicates are to be expected and it can raise several issues:
- Data integrity — you can count your data twice.
- Unnecessary process invocation, which can affect performance and cost.
Duplications may happen for two different reasons:
- The app didn’t ack the message within the deadline.
- Even though the message was ack’ed, Pub/Sub can still send it more than once.
Regarding the first case, assuming you didn’t forget to ack messages within your code:
- If your process time of each message is consistently longer than the subscription’s ACK deadline, increase it for the entire subscription.
- If a specific message takes longer to process you can use the modify_ack_deadline method on that message to increase its ack deadline on the subscription side.
In cases where the duplication comes as a result of Pub/Sub’s internal implementation (rarer) you should pipe it through a component that deduplicates it first. Pub/Sub assigns a unique `message_id` to each message, which can be used to detect duplicate messages received by the subscriber.
Firestore implementation
Redis (Memorystore) implementation
My subscriber code
Delayed Messaging
Google Pub/Sub does not implement any logic for delayed delivery. Messages are delivered as fast as possible.
Message-driven architecture can be used to generate delayed code execution by avoiding implementing a suspension logic and calling wait() from within the app.
So how can we implement delayed messaging without using wait() within our code?
Let’s take a look at our solution for this issue:
We used Cloud Tasks API with Cloud Function to create scheduled tasks that later push messages to the App Engine app (we picked App Engine as our HTTP target for Cloud Task).
To create a queue using the Cloud SDK, use the following gcloud command:
gcloud tasks queues create delay-queue
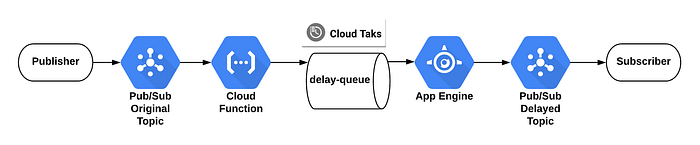
Delayed Messaging Diagram
I will manage two topics in Pub/Sub:
- The origin topic which will receive all messages from the Publisher
- The topic which will get all the delayed messages.
This Cloud Function should be triggered by origin topic and insert future cloud task into the queue:
The App Engine code will be triggered by Cloud Task after delay and publish the message to the final topic:
FIFO Queue
Pub/Sub does not yet implement any logic for order delivery (FIFO, priority).
Messages are delivered as fast as possible, with preference given to delivering older messages first, but this is not guaranteed — oh my what a mess! This design makes Pub/Sub problematic to serve as a trigger for workloads like complex ETLs where the order of the steps is important.
We’ve succeeded in enabling FIFO behaviour using Cloud Firestore in order to save the queue state. Keep in mind that these kinds of systems aren’t supposed to handle high volume streams since ordering has its price, performance-wise.
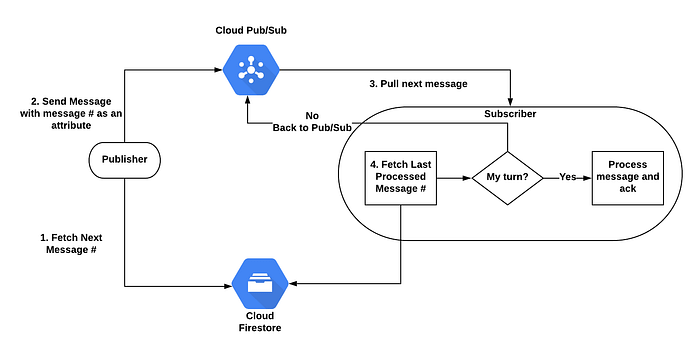
FIFO Flow Diagram
Cloud Firestore will hold two counters:
- The message number — indicating what is the next message number. Each time a publisher sends a message, it pulls the message number, increments it by 1, and sends it as an attribute of the message. The initial value is 1.
- The last message processed — indicating the last message number that was processed. The initial value is 0.
For each message, the publisher performs the following:
P.S. Publisher might throw “Failed to commit transaction in 5 attempts” exception in case multiple publishers work intensively in parallel. You can control the retry parameter by passing a max_attempts argument to the client.transaction() method call.
The subscriber performs the following:
Each message arrived has three options:
- All previous messages were processed so the current message can be processed (delta=1).
- At least one previous message wasn’t processed yet, so the message should go back to the queue for later processing (delta>1).
- This message has already been processed, so we only need to ack it (delta<1). As discussed, earlier messages might be retransmitted for various reasons.
Disclaimer: Current implementation makes sure that each message won’t be processed before the previous message was processed at least once. This means that in extreme cases there can be a situation where a duplicate message is being processed in parallel to the current message. In order to prevent this state totally, you need to integrate the dedupe solution I presented earlier.
Firestore code:
Why Firestore?
On the publisher side, in cases where there is only one publisher, it doesn’t really matter which persistence layer to pick. In the case of multiple publishers, the persistence layer must be an ACID storage system such as Cloud Firestore. Each publisher must get and set the counter in one transaction in order to prevent publishers from sending messages with the same message number.
On the subscriber side, it needs to make sure that other subscribers didn’t change the Last Message Processed counter before it sets the new value.
I hope you find this post useful. I look forward to your comments and any questions you have.