
Introduction
A great perk of working with a Google Cloud Premier Partner like DoiT, is the ability to get early access to new tech — and this time I’m writing about
’s N4A instance family, their Arm-based general-purpose VMs powered by Google Axion Processors.
N4A represents Google’s evolution of their Arm processor portfolio with a crucial distinction. While C4A launched in October 2024 as the performance-optimized Axion-powered instance family, N4A takes a different approach as the cost-optimized Arm general-purpose family. Therefore, Google now offers a “better together” Axion strategy:
- C4A = Performance-optimized Arm for latency-sensitive workloads at $0.0449/hr for 1v/4GB
- N4A = Cost-optimized Arm for general-purpose compute fleets at $0.0385/hr for 1v/4GB
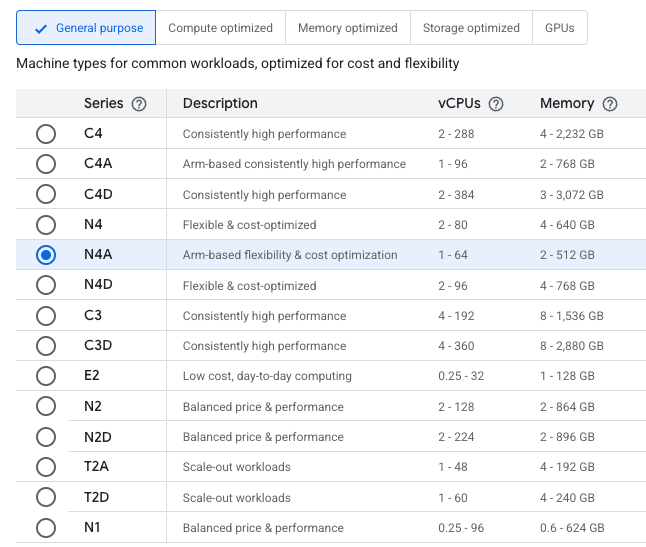
Compute Engine displaying the N4A option
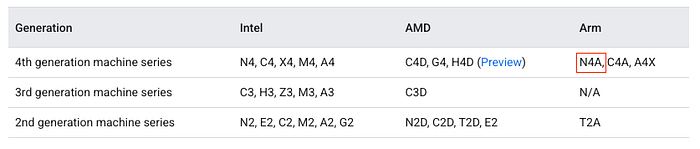
Google Cloud documentation showing the N4A series
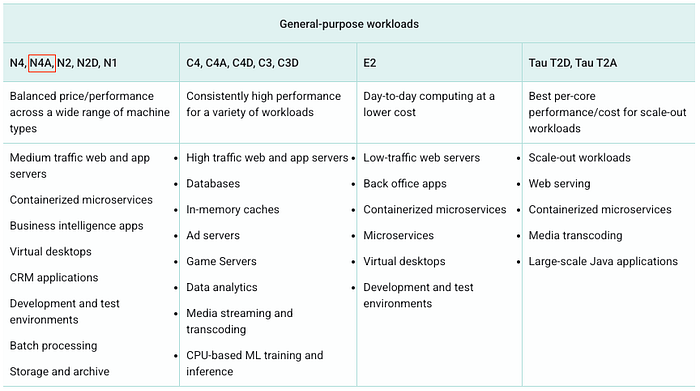
N4A Offering for General-purpose workloads
I spent the last few days putting N4A through its paces against N4, C4A, and AWS’s Graviton4-powered M8g. Here’s what the tests said about whether N4A deserves a spot in your infrastructure.

CLI Listing of VMs running to test
Methodology
All benchmarks in this article were conducted on:
- N4: n4-standard-8 (Intel Xeon 5th Gen — Emerald Rapids)
- N4A: n4a-standard-8 (Google Axion / Arm Neoverse N3)
- C4A: c4a-standard-8 (Google Axion / Arm Neoverse V2)
- M8g: m8g.2xlarge (AWS Graviton4 / Arm Neoverse V2)
Configuration:
- OS: Debian GNU/Linux 13 (trixie)
(ARM64 for Arm instances, x86_64 for N4)
- Kernel: 6.12.48+deb13-cloud-arm64
- Fresh instances, no custom tuning.
Tools used:
Sysbench for CPU computational performance
- Multi-threaded test with 8 threads
- 120-second duration
- Prime number calculation (max 20000)
- Key metric: Events / second
7-Zip for Real-world compression workload
- Multi-threaded compression/decompression
- Tests both compression and decompression performance
- Key metric: Total MIPS rating
OpenSSL for Cryptographic performance
- Tests hardware crypto acceleration (Arm advantage)
- AES-256-GCM and SHA256 algorithms
- Key metric: MB/s throughput
All tests were run multiple times, and results represent median values. Script available at this Gist.
Benchmarks
Sysbench CPU Performance
Pure CPU computational throughput using prime number calculations, higher is better.
N4A delivers the highest raw CPU performance, outperforming both C4A (+13.7%) and M8g (+21.7%). The Neoverse N3 architecture shows excellent computational performance.
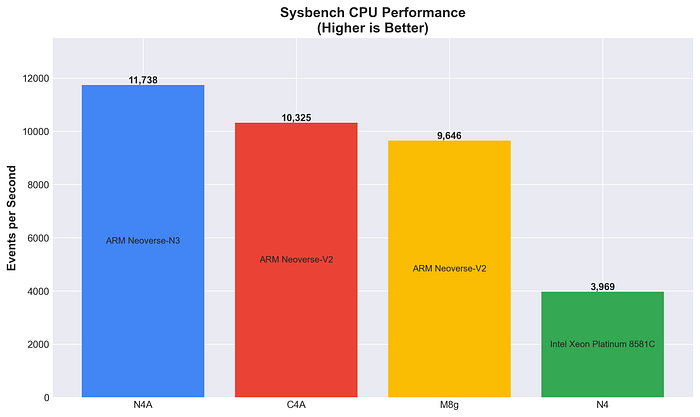
Sysbench CPU Performance
Price-performance ratio
Arm instances show 2.4–3x better computational performance than Intel x86. N4A’s N3 architecture delivers ~14% better performance than C4A’s V2, demonstrating strong computational efficiency in generic workloads.
7-Zip Compression
Real-world compression/decompression performance, very common in cloud workloads, higher is better.
C4A leads in compression workloads, with the rest showing similar performance. All Arm instances significantly outperform N4 in decompression tasks (75–87% improvement), as expected.

7-Zip Compression / Decompression MIPS Rating
- C4A: 768 comp / 8977 decomp
- M8g: 772 comp / 8361 decomp
- N4A: 770 comp / 8471 decomp
- N4: 729 comp / 5114 decomp

7-Zip Overall Performance
C4A’s performance optimization shows in compression workloads. N4A performs similarly to M8g despite being cost-optimized, showing a great balance. Arm’s consistent advantage in compression (75%+ over x86) demonstrates architectural efficiency.
OpenSSL Cryptographic Performance
Hardware-accelerated cryptography performance.
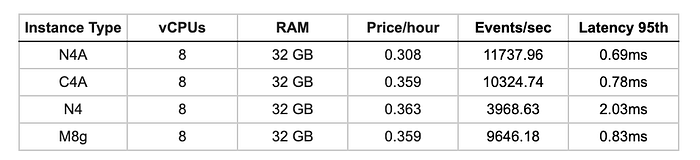
C4A leads in AES-256-GCM and N4 comes in second place (44.5 GB/s) outperforming both M8g and N4A, while also remaining competitive in AES encryption workloads.
OpenSSL AES-256-GCM Performance
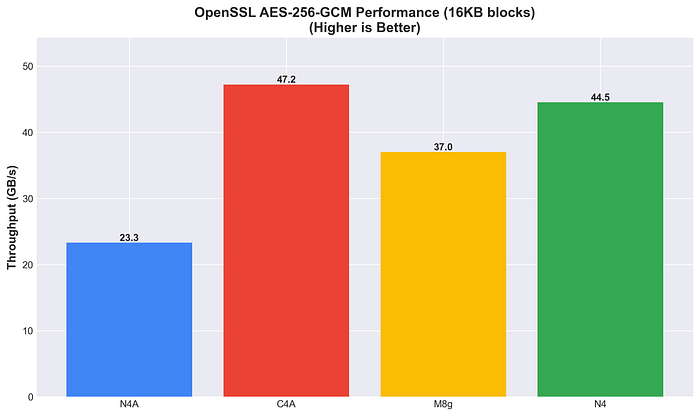
N4A on the other hand leads in SHA256 hashing (19.2 GB/s), showing 2.8x better performance than N4.
OpenSSL SHA256 Performance
Hardware acceleration varies by algorithm. SHA256 hashing shows clear Arm advantages (2–3x), while AES-256-GCM encryption is more nuanced.
Insights
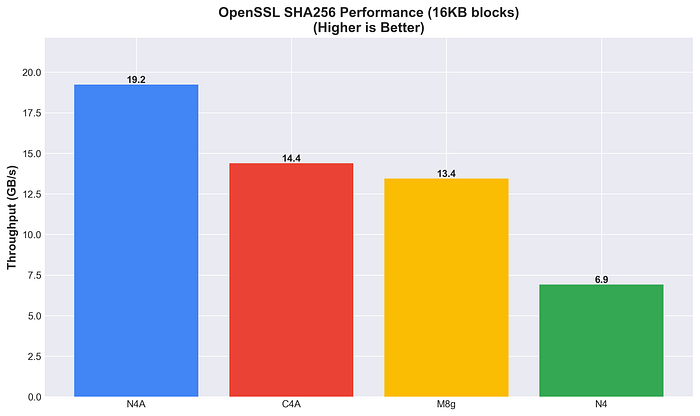
Looking at the full Arm comparison (N4A, C4A and M8g), with N4 Intel serving as the baseline reference.
Arm to Arm Comparison
Relative Performance % of N4, N4A, C4A and M8g instances across a number of stress tests.
N4A Strengths
- Leads in CPU computation (+13.7% vs C4A) and SHA256 hashing (+34% vs C4A)
- Competitive in 7-Zip compression
- Lower AES-256-GCM throughput (-51% vs C4A)
- Right-sizing benefit with Custom Machine Types ( CMT) for cost optimization; A unique feature to N4A across all other Arm platforms available - Graviton 4 is predefined instance size only for example.
C4A Strengths
- Leads in AES-256-GCM encryption (+102% vs N4A) and 7-Zip compression (+6% vs N4A)
- Strong CPU performance, but trails N4A
M8g Position
- Middle ground across most benchmarks
- Trails both N4A and C4A in CPU and hashing performance
N4A, as promised by the Neoverse N3, optimizes for efficiency and computational workloads at cost-optimized pricing. C4A with the Neoverse V2, optimizes for maximum throughput in bandwidth-intensive operations at performance-tier pricing.
Why N4A leads in SHA256 but not AES-256-GCM?
The crypto results also reveal architectural trade-offs.
N4A leads in SHA256 hashing (+34% vs C4A) but lacks a lot in AES-256-GCM encryption (-51% vs C4A).
AES-256-GCM — Throughput-intensive AEAD cipher combining encryption + authentication
- Requires high memory bandwidth and parallel processing
- Benefits from wide execution pipelines and dual-issue crypto instructions.
SHA256 — Compute-intensive iterative hashing
- Sequential operations with limited parallelism (64 rounds per block)
- Low memory bandwidth, benefits from efficient instruction execution
Different crypto operations favor different architectures so you better match your workload to the right instance!
N4A is Google Cloud bringing Arm’s latest efficiency-optimized architecture (Neoverse N3) to market in a cost-optimized package. Our benchmarks show it outperforming both C4A and AWS Graviton4 (M8g) in CPU performance and SHA256 hashing, while being priced for large-scale fleet optimization.
N4A is priced at $0.0385/hr(1v/4GB) in us-central1, that’s 14% less than C4A’s $0.0449/hr. Combined with superior CPU performance, this delivers around ~33% better price-performance for your compute workloads.
By using C4A for your performance-critical workloads and N4A for your general-purpose ones, you can achieve substantial TCO reduction while maintaining or even improving application performance. A 100-instance fleet switching to this “better together” approach can save $48,000+ annually.
Resources: Benchmark Tool | Google Cloud Axion | Arm Neoverse N3
Our mission at DoiT is to help customers continuously optimize their cloud infrastructure, and the new Axion portfolio is a powerful new lever for that optimization. With this new Arm combination, we can architect a “better together” strategy, using C4A for performance-critical workloads while leveraging N4A to help customers cut compute TCO on their largest fleets.

Interested in optimizing your compute fleet with the “better together” Axion strategy? If so, ping me and let’s talk!