
Journey from Ideation to Production — Image from AWS community
Here is a brief map for starting your journey for implementing LLM in your workload. The journey from ideation to production is an exciting journey that is everything but linear. The stages, we will unpack here, will allow you to identify where in the journey you are and how you can move from one stage to another to get to a production environment.
We are going to define 6 stages and the connection between all of them being monitoring and security.

Stages
Ideation
The capabilities of LLMs allow us to explore the world of customization and personal user experience fully. When thinking of the use cases where we can use LLMs, we start thinking of the specific data points to allow us to understand individual customer experience journeys.
Looking at some examples:
- If I could recognize car scratches in images from surveillance cameras in order to improve the check-in and check-out of our rental cars.
- If I knew which services were most likely to retain a customer, I could offer personalized offers to retain the customer.
- If I could identify the customer persona with individual historical data, I could provide expert advice.
We can see that we start at a general level with an aim to provide unique advice based on individual experiences. I encourage you to start with the following template to get the ideas started, and evolve the ideas to more use cases outside of these templates.
- If I could recognize/interpret/identify ______ in ____ I could ____
- If I knew which ________ were most likely to __________ by each individual _______ I could ____
- If I could identify ________ with _______, I could _________
Create a handful of use cases for further evaluation. Even if they may prove difficult to start, keep them. These same use cases can become feasible in the future.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Data Evaluation
Pick one of the first use cases, maybe the one you think would have the best ROI, let’s identify what data is required to get started. Not every required data point will be identified during the first iteration, you may move to later stages just to realize additional data points are required. The important thing is to keep documentation of all the findings to help us in future initiatives.
We take one of the examples we started with in the previous stage.
- If I knew which services were most likely to retain a customer, I could offer personalized retain offers.
We need to identify what data is required in order to start making a prediction. This is where domain knowledge comes into play to help identify the data points.
For this particular example, we start by identifying customer interactions such as service feedback or comments, previous purchases, service views, or service clicks. Any interactions with customer support are also helpful. We may also leverage the information from the customer profile.
At this stage it is better to have too much data than to try to keep data skim and lean. The testing process will allow us to identify what data can be removed, or if we require additional data to achieve the desired results.
Bias Types
Several types of biases can creep up in your data. Here are some to watch for.
Reporting Bias — This happens when the frequency of records in a dataset does not accurately reflect real-world distributions, leading to skewed or biased outcomes. This discrepancy arises when certain events or behaviors are over- or under-represented in the training data.
Selection Bias — To avoid this bias make sure that the data is representative of the target population. This involves collecting diverse and comprehensive data from various sources to cover different demographics, contexts, and scenarios.
Group Attribution Bias — To avoid group attribution bias, ensure your training data includes diverse and balanced representations of all groups. Regularly audit the model outputs for biased patterns and use fairness metrics to assess performance across different groups.
Monitoring & Security
Early in our process we will start incorporating security and monitoring to our workload. It is important to ensure that we are meeting security control in our data pipeline. Follow least privilege principles and audit controls on the data source.
Additionally, ensure monitoring of your data pipelines to decrease the possibility of data integrity issues, and the potential of degraded quality of the machine learning output.
Finally, do a test on bias. Create a test to evaluate the importance of metrics in the representation of the data. Is your data representative of the production data you will receive? Are you including PII data? Are you including any other data that can introduce a bias?
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
Architecture Design
Let us start with your use case for selecting right foundation model.
Amazon Bedrock provides access to various foundation models from leading AI providers that are useful for different generative AI use cases.
Here are the models that can be used for specific cases like text generation/summarization, image generation/identification, audio transcription/translation, and embeddings:
1. Text Generation/Summarization
For tasks like generating or summarizing text, you can use models that are capable of understanding and generating natural language. Examples include:
- Anthropic Claude: Known for advanced text generation capabilities, including summarization, question answering, and dialogue.
- Mistral Models: They are designed to be versatile, and capable of handling various text-based tasks, including generation, summarization, and more.
2. Image Generation/Identification
For generating or identifying images, you need models specialized in computer vision:
- Stability AI Stable Diffusion: Ideal for image generation, capable of creating detailed and high-quality images from text prompts.
- Amazon Rekognition (not part of Bedrock but relevant for image identification): Provides robust image identification, object detection, and facial analysis capabilities.
3. Audio Transcription/Translation
For converting audio to text or translating languages, you would use models adept at handling audio data:
- Amazon Transcribe (not part of Bedrock but relevant for audio transcription): Converts speech to text accurately.
- Amazon Translate: (not part of Bedrock) For translating text from one language to another, can be paired with Amazon Transcribe for end-to-end audio translation.
- OpenAI Whisper foundation model: Available on SageMaker JumpStart. A foundational model that transcribes audio into text very efficiently in multiple languages.
4. Embeddings
For generating embeddings:
- Amazon Titan Embeddings: Specialized in creating dense vector representations (embeddings) of text, useful for semantic search, clustering, and recommendation systems.
With Bedrock, it is possible to run your own model or any other models on Sagemaker, like all of the models available at Huggingface. Here is the reference to models supported on Bedrock.
Once you have selected the right foundation model next part would be to choose the appropriate system design. You can choose one or you can combine some of them to get the right results for your scenario.
1. Direct GenAI model
Here generative AI model is trained to directly generate the desired output from the input. It’s often used in tasks that require general information like the capital city of a country.
2. RAG (Retrieval-Augmented Generation) architecture
RAG combines the benefits of retrieval-based and generative models. It first retrieves relevant documents from a knowledge base and then uses a generative model to create a response, incorporating information from the retrieved documents.
3. Agent architecture
In this design, multiple AI models (agents) interact with each other to generate the final output. Each agent specializes in a different aspect of the task, and they collaborate to produce a more complex output.
4. Multi-model architecture
This involves training a single model that can handle multiple tasks.
It’s particularly useful in scenarios where the tasks are related or have overlapping information.
The choice of architecture depends on the specific requirements and constraints of your project.
There are several AWS services that can be used for your project
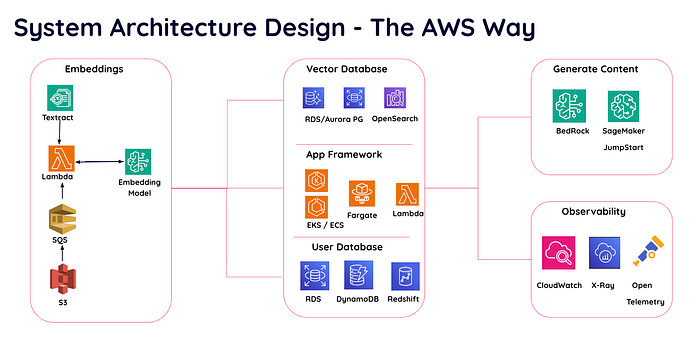
System Architecture Design with AWS services
Prompt Design
Prompt design is important because it influences the quality and relevance of the AI model’s output. A well-designed prompt can guide the model to generate more accurate, contextually appropriate, and useful responses. It is essential for the following reasons
1. Precision:
If your prompt is clear and specific, it can help the model understand exactly what is being asked, leading to more precise responses.
2. Context:
A well-designed prompt provides the necessary context, which can help the model generate responses that are more relevant and meaningful. Do note that context size is limited and with some models also lead to extra costs, because they apply to the token size for input parameters. When you choose a model make sure that it supports the context as not all models support context tokens.
3. Control:
When you need the model to adhere to certain guidelines, a careful prompt design will help to guide the model’s behavior and output.
4. Efficiency:
A good prompt can reduce the need for back-and-forth clarifications, making interactions with the model more efficient.
5. User Experience:
Finally, well-crafted prompts contribute to a better user experience, as they enable the model to provide satisfying responses.
Now that we know the importance of a well-crafted prompt. It’s time to focus on the next steps.
Start with defining the desired output. For example, For a prompt like, “Can you recommend a good Italian restaurant in San Francisco?”, a suitable output might be: “Sure, ‘Trattoria Contadina’ in San Francisco is highly recommended for Italian cuisine. It’s known for its authentic dishes and cozy atmosphere.
Don’t forget to try their signature pasta!”
Identifying the required context for a desired output: Thisinvolves understanding the information necessary for the AI model to generate an accurate and relevant response. Here are some steps to help you identify the required context:
1. Understand the Task: What is the model supposed to do? Is it answering a question, generating a piece of text, or performing some other task? The nature of the task will determine what context is needed.
2. Identify Key Information: What information does the model need to know to perform the task correctly? This could include details provided in the prompt, background knowledge about the topic, or information about the user’s preferences or situation.
3. Consider Dependencies: Are there any dependencies between different parts of the task? For example, if the task is to generate a response to a series of questions, the model might need to remember previous questions and answers.
4. Test and Iterate: Finally, test the model with different prompts and see what kind of output it generates. If the output is not as desired, you might need to provide more context or clarify the prompt.
5. Test with different models: If the end result is not satisfactory, you might want to try a few more models to pick the best.
The final goal is to provide enough context for the model to generate the desired output, but not so much that it becomes overwhelmed or confused. It’s a delicate balance that often requires experimentation and iteration.
To get the desired output create 2–3 best prompts with few shots, chain of thought, or multi-prompt techniques, and choose the one that is best for your requirement.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Security
Once the prompt design phase is completed, focus on the security measures to mitigate prompt injection. As you know already, prompt injection is a security risk where an attacker manipulates the input to the model to produce harmful output like getting access to restricted information. Here are some measures to mitigate prompt injection.
1. Input Validation: Implement strict validation rules for user inputs. This can include length restrictions, format checks, and filtering out special characters or potentially harmful keywords.
2. Sanitization: Sanitize user inputs to remove or escape characters that could be used for injection attacks. This can help prevent the model from interpreting part of the input as a command or instruction.
3. Rate Limiting: Implement rate limiting to prevent rapid, repeated requests from a single user or IP address. This can help mitigate brute-force attempts at prompt injection.
4. Monitoring and Logging: Monitor the system’s activity and log user inputs and model outputs. This can help you detect unusual patterns or signs of an attack.
5. User Education: Educate users about the risks of prompt injection and encourage them to report any suspicious activity. This can help create a culture of security awareness.
6. Model Training: Train your model to recognize and reject potentially harmful inputs. This can be challenging due to the complexity of language and the risk of false positives, but it can be an effective additional layer of defense.
POC (Proof of Concept)
Now that we have information about the managed services available for the project and have a good understanding of the architectures, it’s time to build something exciting.
We can take advantage of AWS Amazon Bedrock, it is the easiest way to build and scale generative AI applications with foundation models. It offers several high-performing models like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, and Stability AI. Also offers various tools like Knowledge bases, Agents, and Guardrails.
Knowledge Bases for Amazon Bedrock: This is a fully managed capability that helps you implement the entire RAG workflow from ingestion to retrieval and prompt augmentation without having to build custom integrations to data sources and manage data flows.
Agents for Amazon Bedrock: Agents orchestrate and analyze the task and break it down into the correct logical sequence using the FM’s reasoning abilities. Agents automatically call the necessary APIs to transact with the company systems and processes to fulfill the request, determining along the way if they can proceed or if they need to gather more information.
Guardrails for Amazon Bedrock: They are used to implement application-specific safeguards based on your use cases and AI policies.
With these tools, it is easy to get started and build a prototype of the system you are planning to build. This would be a good starting point to test out our architecture. Have a few test scenarios to check the results. Try it out using different datasets and request different users to take it for a ride. This part is exciting. You will get compliments, suggestions, and, constructive feedback. If required, go back to the drawing board, modify the model, try different architecture and different services, and select the most appropriate ones. It is not a linear process after all.
At this point, you can make sure that all the observability and security measures are in place. Security is a multi-layered process that involves both technical measures and human factors. It’s important to regularly review and update your security practices to keep up with evolving threats.
So that brings us to the observability and security.
Observability
If you are using LLM for text generation then evaluate against the following
Perplexity:
This is a measurement of how well a probability model predicts a sample. In the context of language models, a lower perplexity means the model is better at predicting the next word in a sequence. It’s often used during the training process to gauge the model’s progress.
BLEU (Bilingual Evaluation Understudy):
This is a metric used to evaluate the quality of machine-generated translations.
It measures how many words or phrases in the machine translation match a reference translation, taking into account both precision (how many words in the machine translation are in the reference) and recall (how many words in the reference are in the machine translation).
ROUGE (Recall-Oriented Understudy for Gisting Evaluation):
This is a set of metrics used to evaluate automatic summarization of texts, as well as machine translation.
ROUGE includes measures to compare the overlap of n-grams, word sequences, and word pairs between the system-generated summary and a set of reference summaries.
Word Error Rate (WER):
This is a common metric for speech recognition and machine translation tasks. It measures the minimum number of edits (insertions, deletions, or substitutions) required to change the system output into the reference output. A lower WER indicates a more accurate system.
Each of these metrics provides a different perspective on the model’s performance, and they are often used together to get a more comprehensive understanding of how well the model is doing.
Observability — User actions
Output satisfaction:
Get user feedback 👍 or 👎
User copies the model output:
Observe if the users copy the output of the model often. This shows they find the output useful.
User regenerates the output:
If you notice that users repeatedly regenerate output by changing the prompt then this behavior may be due to faulty output. Check the prompts to make sure that they give useful output.
How long a user interacts with the model:
If several users tend to spend less time communicating with the model and leave abruptly then maybe they are not satisfied with the model’s performance. In that case, you will have to check the performance of the model.
More Security Measures
Toxicity Evaluation:
You can use Comprehend to analyze text and understand its sentiment, whether it’s positive, negative, neutral, or mixed. This can be used as a part of toxicity evaluation to understand if the text contains harmful or negative content. If your requirements are more specific, you might need to train a custom model using Amazon Comprehend’s custom classification feature. You can train the model with a dataset that includes examples of toxic and non-toxic text, and then use this model to classify new text based on its toxicity. Amazon Transcribe, another AWS service, has introduced a feature called Toxicity Detection.
GuardRail:
Guardrail is a tool included in Amazon Bedrock to build and customize safety and privacy protections for a generative AI application. It works with all large language models (LLMs) in Amazon Bedrock, as well as fine-tuned models. You can set up rules in Guardrail and you can set up multiple guardrails. It sits in between the application and the model and automatically evaluates everything going into the model from the application and coming out of the model to the application to detect and help prevent content that falls into restricted categories.
Custom Entity Recognition:
It is a feature of Amazon Comprehend. This feature allows you to identify terms that are specific to your domain in the text.
For example, you might use Custom Entity Recognition to extract specific types of information from unstructured text documents, such as product names, financial entities, or any term relevant to your business.
You can use this service to filter out certain entities and secure your data.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
Scale the solution:
Quantize models:
Quantization is a process used to reduce the memory and computational requirements of machine learning models. It can significantly reduce the memory footprint of the model and speed up computations, often without a significant loss in accuracy. However, it is important to note that there is a loss in accuracy, but accepted as long as your evaluation metrics are still meet (as example ROGUE, BLEU or own tests).
Fine tune models:
Fine-tuning is a process where a pre-trained model (a model that has already been trained on a large dataset) is trained to perform a specific task. So we can use the learned features of the pre-trained model and adjust them to the new task and thus use less data and computation resources. Fine-tuning will help to improve efficiency, reduce data transfer cost and, promote better utilization of resources.
Multiple Deployments:
Keep Orchestration Framework (ie. LangChain) simple and create multiple deployments to handle complex pipelines.
Evaluate hosted model cost vs api model at very large scale:
Compute Resources required: Check the computational resources required for both options. For a hosted model, this includes the cost of the servers (CPUs/GPUs) needed to run the model. For an API model, this includes the cost per API call or per unit of compute time. They are often metered in tokens and amount of tokens depends on input and context size and model.
Data Transfer: For a hosted model, this includes the cost of transferring data to and from the server. For an API model, this includes the cost of data sent and received from the API.
Storage: For a hosted model, this includes the cost of storing the model and any data. For an API model, this might include the cost of storing data before and after API calls.
Maintenance: A hosted model may require more maintenance, including server management, model updates, and troubleshooting. An API model might have lower maintenance costs as the provider handles these tasks.
Scaling: If your application needs to scale up to handle more requests, a hosted model might require more servers, increasing costs. An API model might scale more easily, but costs will increase with the number of API calls.
Latency: If your application requires real-time responses, a hosted model might provide lower latency. However, if the API provider has servers close to your users, an API model might offer comparable latency.
After considering these factors, you can estimate the total cost of ownership (TCO) for both options. This will give you a clearer picture of which option is more cost-effective for your specific use case.
However, cost is not the only factor to consider. Please also consider factors like performance, flexibility, and ease of integration with your existing systems.
Summary:
This blog outlines a 6-stage process for going from ideation to production with large language models (LLMs):
- Ideation — Brainstorm use cases and ideas for leveraging LLM capabilities. The document provides a template to help generate ideas.
- Data Evaluation — Identify the data required to support the selected use case, being mindful of potential biases in the data.
- Architecture Design — Choose the appropriate AWS services and foundation models from Amazon Bedrock to build the required functionality. Options include direct generation, retrieval-augmented generation, agent-based, and multi-model architectures.
- Prompt Design — Carefully craft prompts to guide the model and ensure the desired output quality, while also considering security measures to mitigate prompt injection risks.
- Proof of Concept (POC) — Build a prototype using Amazon Bedrock’s tools like Knowledge Bases, Agents, and Guardrails, and test it thoroughly.
- Observability and Security — Implement measures to monitor model performance (e.g., perplexity, BLEU, ROUGE) and user interactions. Also, incorporate security controls like toxicity evaluation and custom entity recognition. It emphasizes the importance of incorporating monitoring and security considerations throughout the entire process. It also provides guidance on scaling the solution, including techniques like model quantization and fine-tuning, as well as evaluating the trade-offs between a hosted model and an API-based approach.
This blog is a brief summary of a webinar Eduardo Mota and I did for the customers of DoiT International. He is the co-author of this blog post.
If you would like to start your LLM journey, let’s chat!