
Cloud MLOps for speed and efficiency
A revolutionary machine learning algorithm, developed during your university years, predicts basketball game winners by analyzing game data and fan sentiment. This breakthrough forms the foundation of your new startup. Initially, development is manageable — your algorithm thrives on a single virtual machine, whether in the cloud or on your laptop, thanks to the limited data.

Getting out of hand
However, as your startup gains traction, signing multiple leagues and attracting a growing customer base, the data influx explodes. The initial simplicity gives way to the complexities of managing multiple VMs 24/7, grappling with security, and applying OS patches. Growth, while exhilarating, becomes overwhelming. Tracking daily model training, performance, and deployment decisions becomes a significant challenge. Which model should you deploy for optimal customer service?
I will describe the many Machine Learning Operations (MLOps) services offered by cloud platforms like Google Cloud Platform (GCP), Amazon Web Services (AWS), and Azure, designed to address these scaling hurdles.
While the sheer number of services can be daunting, I will explain how to decide when to adopt a new service, just when you need it.
The breadth of MLOps
The diagram below illustrates key MLOps steps (many more exist, but these are among the first you will adopt). These steps always exist — you might be performing them manually. The challenge lies in identifying when cloud services can automate and streamline them.
All major cloud providers offer comparable suites: Google Vertex AI, AWS SageMaker, and Azure Machine Learning. While details differ, the services play a similar role in your transition to automated MLOps.
The Basics
Let’s take the steps in the typical adoption order, starting with development, training, and prediction.
Development
Initially, Jupyter Notebooks on your laptop or a VM likely suffice. However, this necessitates paying for compute resources constantly. Cloud-based development platforms like Vertex AI Workbench, SageMaker Studio, or AzureML Notebooks provide a better alternative. They offer the familiar Jupyter interface but with pay-as-you-go pricing, and are activated only during your work hours. Pre-built environments with essential tools (e.g., TensorFlow) are included, simplifying collaboration and eliminating the burden of infrastructure maintenance, including security patches.
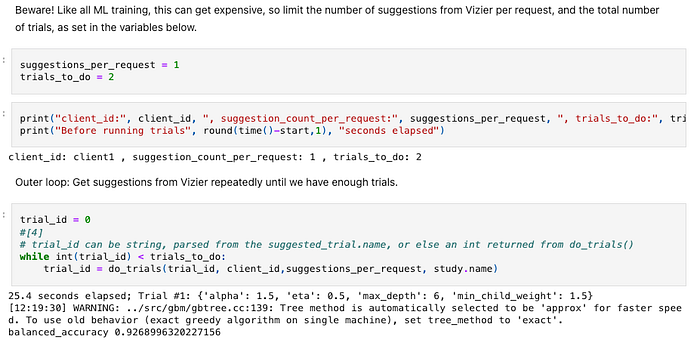
Example Notebook: No functions, but rather linear code mixed with outputs
Two cautions about Notebooks
1. Although the clouds have services that run notebooks as pipelines, don’t do it: Notebooks are for interactive development, not runtime. Their sequential, often unstructured code is hard to maintain and outputs that are interspersed with code (for example, the balanced_accuracy metric of 0.9268996320227156above) hinder version tracking. Use notebooks for development, but use pipelines for execution.
2. For computationally intensive tasks like training, leverage cloud services instead of the notebook’s resources. This avoids paying for idle CPU, GPU, and memory throughout the workday. Let the cloud handle the heavy lifting.
Training
Training is often resource-intensive. Cloud training services provide an API to offload training to scalable cloud resources. The service scales up the compute resources, and you pay only for the consumed compute resources (GPU, CPU, memory) during the actual training run. You pass a Docker container into the API, allowing the service to run your custom algorithm. Alternatively, if you are using standard algorithms, you don’t even need to create the container: Just tell the service what algorithm to use.
Prediction (Inference)
Prediction is the use of your model for its purpose: For example, predicting game results. A self-hosted web server may suffice initially, but as you gain new fans, move to a cloud prediction endpoint. These services offer automatic scaling, security, monitoring, and performance tracking.
Prediction services offer two variants that a simple homemade endpoint might not have: When you want a quick answer on a single query, an on-demand endpoint gives the lowest latency. But when you have thousands of queries to run, a batch endpoint has a higher throughput of queries per second, though any given answer will take longer.
Beyond the Basics: Scaling MLOps
Development, training, and prediction form the core; however, managing complexity requires additional MLOps services. The cloud ML suites offer solutions to simplify the task. You can use each of these independently of the others through REST interfaces and software libraries; but if you choose to use multiple services, you get built-in integration that makes them easier to use.
Metadata
You might train a new model a day, plus a few experimental variants, and that quickly adds up to hundreds. Listing them in a spreadsheet becomes inadequate. Model registries and metadata stores provide a solution.
Store model files in object storage (Amazon S3, Google Cloud Storage, Azure Blob Store) and use the registry to track them, along with crucial metadata: like the date of creation.
Beyond that, metadata stores can link together artifact lineage. You can track:
- The data behind the model: Did a given model’s training set include the championship quarter-finals data?
- The hyperparameters for training: Which generate the best results?
- Code: Which exact git commit holds the code that ran your custom algorithm?
- Endpoints: Which version of the model was serving predictions to the customer on the day before the basketball quarter-final?
Monitoring
Built-in monitoring during training and prediction lets you track performance in real-time; it enables automated model selection and canary deployments, ensuring seamless transitions and performance optimization.
Continuous monitoring post-deployment detects performance degradation. For example, the model may have been built with skewed data, or results can drift as real-life data changes — say, a new team is promoted to the top league. The monitoring lets you automatically swap in a newly trained model as needed.
Pipelines
Early-stage startups often manage machine learning workflows manually: coding, training, deploying, versioning models, and monitoring performance. This becomes unsustainable as the project scales. A repeatable process is crucial, and cloud-based ML pipeline services like Google Vertex AI, AWS SageMaker, and Azure Machine Learning provide the solution. These aren’t simple sequential scripts; they manage complex dependencies and parallelization. For example, they can automatically split data into training, testing, and validation sets, then execute training and validation in parallel. Deployment is conditional; models are deployed to a canary endpoint only after successful validation, then fully rolled out based on positive ML metrics.
Example pipeline flow
Pipelines add robustness by logging and monitoring all activities. On encountering errors, they can automatically retry, revert to simpler functionality, or terminate the run. Furthermore, they mitigate backpressure — situations where a pipeline component is overwhelmed by data inflow — through configurable buffering mechanisms.
When to Adopt
Those are just a few of the services offered by cloud ML suites, and there are dozens more. I advise you to adopt them. Each boasts a dedicated product team attuned to the needs of thousands of ML developers, and a robust operations team ensuring consistent uptime. Adopting an existing service is significantly simpler than building your own from scratch.
But realistically, you cannot adopt them all at once: You are too busy with the systems you have today.
The key is to move to a service exactly before you fall into the “tarpit” of custom solutions. Integrate an MLOps service just before you’re about to invest significant effort in a homegrown equivalent. This gives you a robust, feature-rich infrastructure and prevents an endless cycle of re-creating features already available.
Consider some scenarios:
- Your development currently involves Jupyter Notebook-triggered training and validation. Adding two data scientists necessitates collaboration and shared workflows. You might contemplate a Git-based solution with custom scripts. Stop! While this approach might initially suffice, it will rapidly become unwieldy. Instead, leverage integrated notebook, training, and prediction services to create a robust, distributed system.
- Similarly, tracking models in a Google Sheet might be adequate initially. But as you grapple with linking models to datasets and resort to the Google Sheets APIs, it’s time for a change. Adopt a model registry and metadata repository before the complexities become overwhelming.
- Likewise, deploying a prediction endpoint on a virtual machine (VM) is straightforward. However, daily traffic fluctuates with the rhythm of the basketball leagues, tempting you to add more machines. If you try automating this, you risk replicating features already inherent in a dedicated prediction service, which typically includes auto-scaling, ML monitoring, and multi-version management.
ML requires MLOps
You are the world’s best in your area of specialization–in this case, in predicting the outcome of basketball games. But your relative advantage is not in setting up the systems that run your ML lifecycle. The moment you realize that you are about to develop an MLOps system, take a look at the cloud and adopt the relevant service.
Talk to us!
This article is based on quite a few conversations that I have had with fast-growing ML companies. For more, come talk to me and my colleagues about your ML challenges: doit.com/services