
The Series
This is a series of articles about replicating data from your traditional database (SQL or NoSQL) into a platform-agnostic data lake (or data lakehouse, depending on who you ask) for your more analytics-based workloads. Throughout it, I will be showing the theoretical architecture, building up the framework for it, and lastly giving a real-world example of implementing this from a Postgres database.
The idea for this series of articles came about while helping a couple of customers in succession get data from their Postgres databases into Iceberg tables to be queried by their BI tooling. After doing multiple sessions covering the same topic, I decided this needs to be written down as I couldn’t find a good step-by-step on it.
As a bonus, I am going to be using strictly open-source software here and off-the-shelf services from the cloud vendors, so it will be as cloud platform agnostic as possible.
Now let’s get this show on the road and dive in!
The Scenario
You are starting to reach critical mass where your transactional data is living in one or more traditional databases, and your data team is starting to have issues doing their jobs with the data being in multiple places and not transformed for their needs. In addition, they are looking at using a data warehouse for their analytical workloads that won’t work with the existing databases.
Your data team is also showing you that growth is going to be picking up, further exacerbating this issue, so the time is now to start transforming your data and storing it in a data warehouse.
So you are seeing the big names out there like Google BigQuery, Snowflake, Databricks, DuckDB, ClickHouse, and Redshift, but you are completely overloaded by choices and want to make the decision that will allow you to be platform agnostic for this.
If this sounds familiar, then have I got some news for you: carry on reading!
If you aren’t in this boat, but want to learn more about creating a platform-agnostic data warehouse (or data lake, technically), then carry on reading as well.
The (Abstract) Architecture
In this series, I will be showing a reference architecture and a sample implementation of getting data from a traditional RDBMS database into a data lake on a cloud provider’s BLOB storage in Apache Iceberg format, which a data warehouse system can then utilize for day-to-day operations.
The reference architecture is very simple and looks something like this:
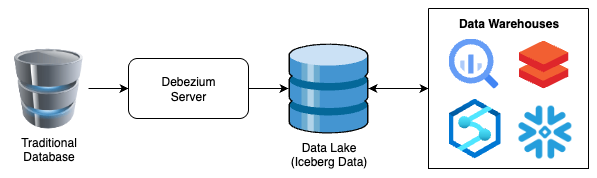
As can be (and typically is) predicted, there is going to be a lot more to it than this, but this very simple diagram shows the power of this process and also shows the platform agnosticism that can be achieved by this.
This is also going to be the super simple version of this, replicating raw data to an Iceberg table without transforms. This is by design for the simplicity of this article. I will put notes on how and where to implement further enhancements to add the T in ETL in later parts of this series, but for this article’s sake, let’s Keep It Simple, Stupid.
The Pieces of This Puzzle
I am going to go over each piece of what the example system I am showing here is to define the pieces, and also show the definition I will be using of some of the modern buzzwords that float around.
Traditional
This will be your database system that your applications use. It will generally be for things such as transactions (think purchases, clicks on a page, audit entries, etc.) or for storing application data.
If you are coming from the traditional relational database world, this will probably fall under a class of database called Online Transaction Processing (OLTP), which, at its core, is a fancy way of saying it handles transactions very well. Some examples of these are MySQL, Microsoft SQL Server, PostgreSQL, MariaDB, Oracle Database, and IBM DB2. There are countless others out there, but these are the main ones that are still around today.
If you are coming from the non-relational, or NoSQL, world, then there can be a few different options. As long as it is supported by Debezium, then it will work. As of the time of this writing, that list is MongoDB, Cassandra, Google Spanner, and anything that has a compatibility layer for utilizing them as a data source.
Data Warehouse
This will be the product that performs the querying and analytics processing for you. This will probably fall under a class of database called OLAP or Online Analytics Processing (OLAP), which, at its core, is a fancy way of saying it handles analytics workloads and processes very well. Examples of these are Google BigQuery, Snowflake, Databricks, DuckDb, ClickHouse, Amazon Redshift, and Microsoft Azure Synapse.
Note: In the context of this article, I am only using the data warehouse for the compute side of things, not for storage. Hence why I didn’t go into detail on that.
Data Lake
This is the location where you store all of your raw data for consumption and where you write your results for transformations that will be read for your analytics processes.
Many times this is a hodge-podge of file formats, but I HIGHLY recommend standardizing on a single format such as Apache Iceberg. This is one of the main reasons that Iceberg and its brethren were created to help standardize data lake storage formats.
A data lake often lives on a class of storage devices called BLOB (stands for B inary L arge OB ject) storage. In simpler terms, this is an almost infinite-sized hard drive that lives in a cloud environment (or on some on-premise data center systems).
Some of the most common examples of this are AWS Simple Storage Service (S3), Google Cloud Storage, Azure Blob Storage, Oracle Object Storage, or Digital Ocean Spaces Object Store.
Apache Iceberg
Apache Iceberg is a data storage format that works very well for storing slow-changing data (read as data warehouse-style data) on BLOB storage devices, allowing analytical databases to query and interact with it seamlessly as if it were natively stored in that database’s storage format. It acts as a common format for data lakes to achieve data platform agnosticism, or at least as close to it as you can get right now.
Note that it should be mentioned that Iceberg is great for analytical queries, but I would HIGHLY advise against using it for transactional workloads. Fivetran has this article, which covers the basics of row versus columnar databases, which directly correlates to the why of this.
It’s a lot more complicated than that, but this is the simplest explanation for it. If you wish to know the full feature list and more, I recommend reading the official docs here.
The Why?
In this day and age, there are MANY choices on the data warehousing front, just to list a few: BigQuery, ClickHouse, Snowflake, Databricks, DuckDB, Redshift, Firebolt, and Synapse Analytics.
Each of these data warehouses, by default, use their own proprietary format for storing the data, so that means you are locked into them, and some are locked into the cloud they are exclusive to. This also means that this data is siloed and unable to be read by other competing data warehouses or other tools that aren’t tied to that platform.
This means it is to your benefit to store data in a common format that can be read by multiple platforms or tools.
This scenario is also a true story based upon reality, a few years ago. If tomorrow vendor X raises their price by 2x+ and gives you 90 days till these costs are fully realized, then one of the largest migration steps has been done for you: storage. You would only need to worry about the compute aspect of your data warehouse instead of the entire ecosystem.
The other unspoken benefit to using a common format is reduced data team costs. It’s something that isn’t brought up enough, but if your data teams have a single data format to work with in a single environment, then that greatly reduces complexity and their time to implementation. It all comes back to cost, so in short, the faster the team can implement, the lower the overall team cost.
The How?
I will be showing an example of how to implement this in Part 2, but here is a rough overview of how this looks.
Instead of storing data in the native format of your data warehouse, you will instead store data in a common format (in this case, Apache Iceberg) in a common storage bucket that is broken up into a logical partitioning scheme. So you will have a single source of truth in a single location.
As the single source of truth, it is directly queried by data warehouse tools, and changes are reflected in new tables in this same format. It’s a cycle that keeps things simple and prevents a lot of complexities that stem from proprietary solutions.
Since there is a single location and single format for this source of truth, a lot of the complexities are simply abstracted away to the infrastructure, allowing you to focus on the data instead of the platform.
Coming Up in Part 2
In Part 2 of this series, I will be diving into how to implement the replication of data from a traditional database into an Iceberg table as the basis of a data warehouse.
How We DoiT
Here at DoiT International, we tackle problems like this all of the time, and I am always asked about ways to help save money while implementing data projects.
Helping out on implementing projects in the most effective and in the most cost effective way is part of our mission for our customers. Handling everything from cases like these to providing the best FinOps solutions for our customers is what we do, and I may be a little biased in saying this, but we do it VERY well.