
Teams, die Kubernetes im großen Stil betreiben, vertrauen auf uns
In wenigen Minuten angebunden
Ein schlanker Agent. Jeder Namespace abgedeckt.
Rollen Sie den DoiT-Collector per Helm-Chart auf Ihre EKS-, GKE- oder AKS-Cluster aus. Wir verknüpfen die Nutzung auf Pod-Ebene mit Ihren Cloud-Abrechnungsdaten – so erscheinen Kosten nach Namespace, Label und Workload direkt neben Ihren übrigen Cloud-Ausgaben. Ohne Custom-Exporter, ohne weitergeleitete Metriken.
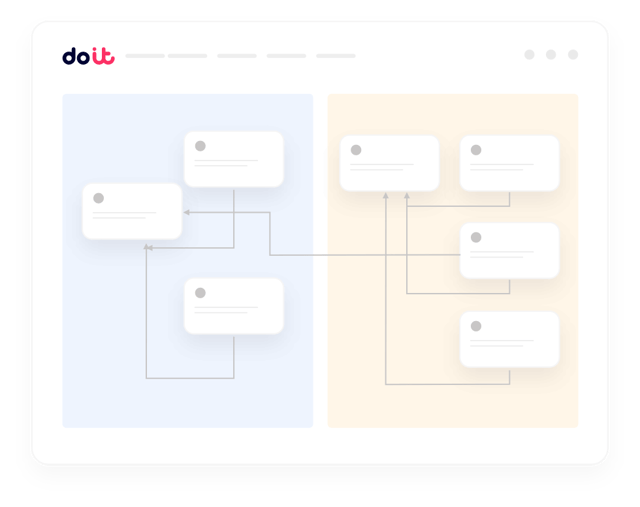
Was Sie bekommen
Gebaut für den Alltag mit Kubernetes
Genau das, worum FinOps- und Platform-Teams uns bitten, sobald sie ihre Cluster anbinden.
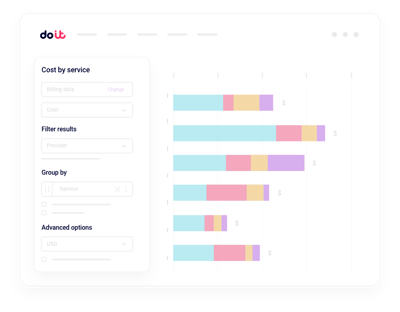
Namespace- und Workload-Zuordnung
Weisen Sie Cluster-Kosten dem Namespace, Deployment oder Label zu, das sie tatsächlich verursacht hat – ohne SQL, ohne Rebuilds.
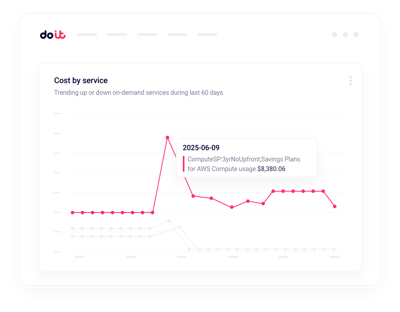
Cluster-Anomalien
Lassen Sie sich benachrichtigen, sobald ein Namespace oder Workload ungewöhnlich viele Ressourcen zieht.
Container-Right-Sizing
CPU- und Memory-Empfehlungen pro Workload – basierend auf realen Requests und Nutzungsmustern.
Idle-Pod-Erkennung
Deckt Deployments und Jobs auf, die bereitgestellt sind, aber nichts Sinnvolles tun.
Node- und Autoscaler-Einblicke
Verstehen Sie die Effizienz Ihrer Node-Pools, erkennen Sie Bin-Packing-Verluste und sehen Sie, wo Spot oder Autoscaling Ihre Rechnung senken können, ohne die Zuverlässigkeit zu gefährden.
Team-Chargeback und Budgets
Verteilen Sie geteilte Cluster-Kosten auf Teams und setzen Sie Budgets pro Namespace – ohne der Label-Hygiene hinterherzujagen.
Native Tools zeigen Ihnen, was ein Pod verbraucht. Cloud Intelligence™ macht daraus konkrete Kostenentscheidungen.
Mehr als kubectl top und Cloud-Rechnungen
Multi-Cluster-Rollups
Konsolidierte Sicht über alle EKS-, GKE- und AKS-Cluster – mit Drilldown in jeden Namespace oder Workload.
Workload-Anomalien in Echtzeit
Machine-Learning-Erkennung auf Namespace-, Workload- und Label-Ebene – direkt in Slack oder per E-Mail.
Right-Sizing und Kapazitätsplanung
Simulieren Sie Änderungen an CPU, Memory und Replicas gegen echten Traffic, bevor Sie sie in Produktion bringen.
Label- und Allocation-Hygiene
Spüren Sie ungelabelte Kosten auf, setzen Sie Allocation-Regeln durch und teilen Sie Shared Services so, wie Finance es erwartet.
Cloud-native Kostenzuordnung
Verknüpfen Sie Pod-Nutzung mit den zugrunde liegenden Kosten von EC2, GCE oder Azure VMs – jeder Container bekommt einen echten Geldbetrag.
Forward Deployed Engineers
Erstklassige Cloud-Architekten, die als verlängerter Arm Ihres Teams Optimierungen direkt umsetzen.
Schnell wachsende Unternehmen setzen auf DoiT Cloud Intelligence™
Durchschnittliche Einsparung in den ersten 90 Tagen
Durchschnittliche Implementierungsdauer
“Der Fokus von DoiT auf Zuverlässigkeit in Kombination mit der Flexibilität des Systems erlaubt uns, unsere Amazon-EKS-Workloads sicher zu optimieren – ganz ohne Zutun unserer Engineers.”
Oren Ashkenazy
Director of DevOps and Cloud bei Fiverr
Bereit für passgenaue Cluster?
Machen Sie aus Pod-Nutzung Einsparungen auf Workload-Ebene.
Frequently asked
questions
Wie verteile ich Kubernetes-Kosten auf Namespaces und Teams?
Cloud Intelligence™ verknüpft die Nutzung auf Pod-Ebene mit Ihrer Cloud-Rechnung – so sehen Sie die exakten Kosten pro Namespace, Deployment, Label oder Team. Geteilte Cluster-Kosten (Control Plane, System-Pods, Idle-Kapazität) werden nach Regeln aufgeteilt, die Ihr Finance-Team auch wirklich verteidigen kann.
Wie binde ich meine Kubernetes-Cluster an Cloud Intelligence™ an?
Installieren Sie unser Helm-Chart in jedem Cluster. Der Collector streamt Pod-, Node- und PV-Nutzung an DoiT, wo sie mit Ihrer bestehenden Cloud-Billing-Integration zusammengeführt wird. Die meisten Teams sehen ihren ersten Report auf Namespace-Ebene noch am selben Tag.
Kann ich Pods per Right-Sizing anpassen, ohne Workloads zu beeinträchtigen?
Ja. Die Empfehlungen basieren auf realen CPU- und Memory-Nutzungsmustern über einen längeren Zeitraum – nicht auf einer Momentaufnahme. Sie können Vorschläge pro Workload prüfen, zunächst in Nicht-Produktionsumgebungen testen und nur das ausrollen, was sicher ist.
Wie erkenne ich Kubernetes-Kostenanomalien, bevor die Rechnung eintrifft?
Die Anomalie-Erkennung läuft kontinuierlich auf Namespace-, Workload- und Label-Ebene. Wenn ein Deployment plötzlich seinen Node-Verbrauch verdoppelt oder ein Runaway-Job hochskaliert, erhalten Sie eine Slack- oder E-Mail-Benachrichtigung inklusive der wahrscheinlichen Ursache.
Was unterscheidet das von kubectl top, Prometheus oder den Bord-Tools der Cloud?
Diese Tools zeigen Nutzung oder Rohrechnungen, aber keine Kosten pro Workload. Cloud Intelligence™ kombiniert Nutzung mit Preisen, Commitments und Shared-Cost-Regeln – für cent-genaue Zuordnung, Right-Sizing und Governance an einem Ort.
Funktioniert das mit EKS, GKE und AKS?
Ja. Derselbe Collector und dieselben Reports laufen für Managed Kubernetes auf AWS, Google Cloud und Azure sowie für selbstverwaltete Cluster. Sie erhalten eine einheitliche Sicht, auch wenn Workloads auf mehrere Clouds verteilt sind.
Kann ich Spot, Autoscaling und Commitments offensiver einsetzen?
Cloud Intelligence™ zeigt, wo Workloads sicher auf Spot laufen können, wo Node-Pools überdimensioniert sind und wie Savings Plans, CUDs oder Reservations auf Ihre Kubernetes-Nodes angerechnet werden – damit Sie mit Sicherheit committen und autoskalieren können.
Sind meine Cluster-Daten sicher?
Der Collector nutzt RBAC nach dem Least-Privilege-Prinzip und liest ausschließlich Metadaten und Nutzungsmetriken – niemals Ihre Anwendungsdaten. Die Plattform ist SOC 2 Type II zertifiziert, und wir nehmen ohne Ihre Freigabe keinerlei Änderungen an Ihren Clustern vor.