
AI-Teams mit geschäftskritischen GPU-Ausgaben vertrauen auf uns
In wenigen Minuten angebunden
Ein Service-Account. Volle Transparenz über Nebius.
Binden Sie Ihren Nebius-Tenant über einen Read-only-Service-Account an. DoiT übernimmt Billing-Daten, GPU-Nutzung und Managed-Kubernetes-Metriken automatisch – ohne Agents, ohne Code-Änderungen und ohne Weiterleitung von Rechnungsdaten. Wenige Stunden nach der Anbindung haben Sie konsolidierte Reports vor sich.
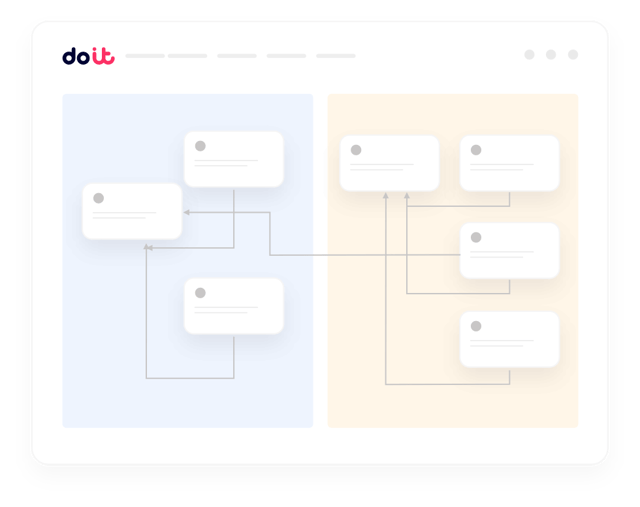
Das bekommen Sie
Gemacht für den AI-Alltag auf Nebius
Genau das, worum uns FinOps- und ML-Platform-Verantwortliche bitten, sobald sie ihre Nebius-Umgebung anbinden.
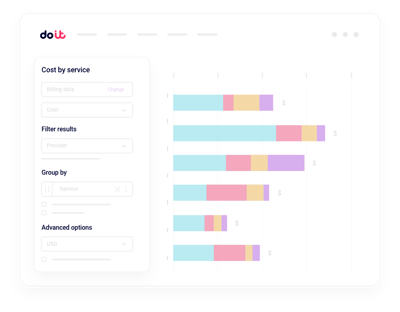
Einheitliches AI-Kostenreporting
Nebius-Ausgaben nach Projekt, Label, Service oder Team aufschlüsseln – ganz ohne eigene Billing-Pipelines.
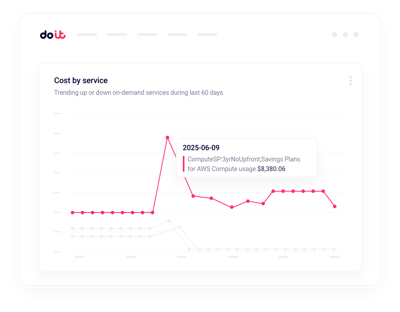
Anomalien in Echtzeit
Benachrichtigungen zu GPU-Kostenspitzen in Minuten – nicht Stunden.
Einblicke in die GPU-Auslastung
Ungenutzte H100- und H200-Instanzen erkennen – damit Sie fürs Training zahlen, nicht fürs Warten.
Cluster-Right-Sizing
Slurm- und Kubernetes-Cluster passgenau auf den tatsächlichen Workload-Bedarf zuschneiden.
Transparenz bei Storage und Egress
Kosten für Object Storage, Snapshots und Datentransfer sichtbar machen, die sich sonst hinter Trainings-Jobs verstecken.
Governance und Budgets
Richtlinien und Budgets pro Research-Team definieren – ohne ständig hinter der Label-Hygiene herzulaufen.
Die Nebius-Konsole zeigt Ihnen, was Sie ausgegeben haben. Cloud Intelligence™ sorgt dafür, dass Sie etwas daraus machen.
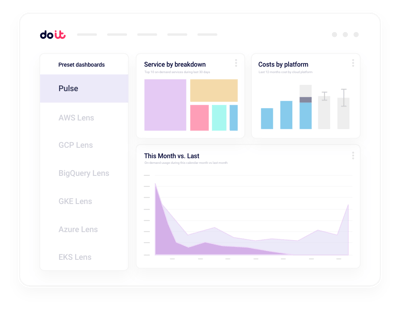
Mehr als nur die Nebius-Billing-Konsole
Projektübergreifende Auswertungen
Konsolidierte Sicht auf alle Nebius-Projekte, mit Drilldown auf Team-, Cluster- oder Workload-Ebene.
Echtzeit-Alerts bei Anomalien
Machine-Learning-Erkennung auf Service-, Projekt- und Label-Ebene – zugestellt per Slack oder E-Mail.
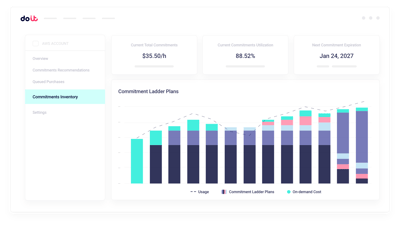
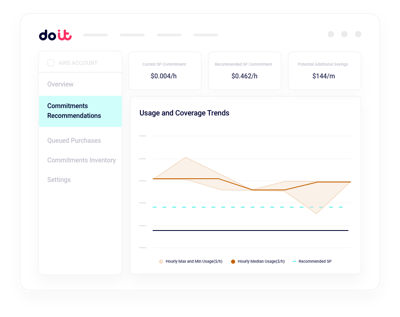
GPU-Kapazitätsplanung
Reservierte GPU-Kapazität gegen die tatsächliche Trainings- und Inferenz-Nachfrage modellieren, bevor Sie sich festlegen.
Label- und Allocation-Hygiene
Nicht gelabelte Ausgaben aufspüren, Allocation-Regeln durchsetzen und geteilte AI-Kosten so aufteilen, wie es Finance erwartet.
Kubernetes-Kostenzuordnung
Managed-Kubernetes-Ausgaben nach Namespace, Workload und Label aufschlüsseln – ohne zusätzliche Exporter.
Forward Deployed Engineers
Erstklassige Cloud-Architekten, die als verlängerter Arm Ihres Teams Optimierungen umsetzen.
Schnell wachsende Unternehmen setzen auf DoiT Cloud Intelligence™
Durchschnittliche Einsparung in den ersten 90 Tagen
Durchschnittliche Implementierungszeit
“Die Zuverlässigkeit von DoiT und die Flexibilität der Plattform sorgen dafür, dass wir unsere Amazon-EKS-Workloads sicher optimieren können – ganz ohne Zutun unserer Engineers.”
Oren Ashkenazy
Director of DevOps and Cloud bei Fiverr
Bereit, Ihren Nebius-Tenant anzubinden?
Nehmen Sie Ihre GPU-Ausgaben unter die Lupe.
Frequently asked
questions
Wie bekomme ich mehr Transparenz über Nebius-Kosten hinweg über mehrere Projekte?
Binden Sie Ihren Nebius-Tenant einmal an. Cloud Intelligence™ zieht die Billing-Daten aller Projekte automatisch ein – so schlüsseln Sie Kosten aus einer einzigen Ansicht nach Projekt, Label, Service oder Team auf, ohne Spreadsheets und manuelle Auswertungen.
Wie binde ich Nebius-Billing-Daten am besten an Cloud Intelligence™ an?
Über einen Read-only-Service-Account mit Zugriff auf Ihre Billing- und Usage-APIs. DoiT übernimmt Ingestion, Normalisierung und detailliertes Reporting. Die meisten Teams sind innerhalb eines Tages live.
Wie erkenne ich, welche GPU-Instanzen oder AI-Services den Großteil meiner Ausgaben verursachen?
Mit den Cost & Usage Reports drillen Sie von den Gesamtausgaben bis auf eine einzelne GPU-Instanz, einen Managed-Kubernetes-Cluster oder einen Object-Storage-Bucket herunter. Sie filtern nach Labels, Projekten oder Regionen – ohne eine einzige Zeile SQL.
Wie überwache ich Nebius-Kostenanomalien in Echtzeit?
Die Anomalie-Erkennung läuft kontinuierlich über Services, Projekte und Label-Dimensionen. Wenn etwas aus dem Ruder läuft – etwa ein Trainings-Job, der übers Wochenende durchläuft – erhalten Sie einen Slack- oder E-Mail-Alert samt wahrscheinlicher Ursache.
Wie steigere ich die GPU-Auslastung und reduziere Leerlaufzeiten?
DoiT deckt unterausgelastete GPU-Instanzen und Cluster auf und zeigt Workloads, die zwar bereitgestellt sind, aber nicht trainieren. Sie bekommen konkrete Empfehlungen, um ungenutzte Kapazität zu verkleinern, zu konsolidieren oder abzuschalten.
Wie bekomme ich mehr Transparenz über Nebius-Storage- und Egress-Kosten?
Object Storage, Snapshots und Datentransfer werden pro Workload und Quelle aufgeschlüsselt. So sehen Sie genau, welche Trainings-Pipeline oder welcher Inferenz-Endpunkt das Volumen erzeugt.
Worin unterscheidet sich Cloud Intelligence™ von der nativen Nebius-Billing-Konsole?
Die Nebius-Konsole ist eine Billing-Ansicht. Cloud Intelligence™ ist eine Plattform: Multicloud-Transparenz, proaktive Empfehlungen, Echtzeit-Anomalie-Erkennung, Governance, Kapazitätsplanung und Zugang zu Forward Deployed Engineers, die Ihnen helfen, aus den Daten echte Maßnahmen zu machen.
Sind meine Daten sicher, wenn ich meinen Nebius-Tenant anbinde?
Cloud Intelligence™ arbeitet mit einem Read-only-Service-Account nach dem Least-Privilege-Prinzip. Wir verschieben keine Workloads und nehmen keine Änderungen ohne Ihre Freigabe vor. Die Plattform ist SOC 2 Type II zertifiziert.