
Vom Signal zum stabilen Betrieb
Wir verbinden Automatisierung mit Forward Deployed Engineers, damit Ihre AWS-Services zuverlässig, sicher und effizient laufen.
Mehr als nur Alerts
Weniger Rauschen. Mehr Fixes.
Wir schicken keine Alerts – wir helfen Ihnen, Fixes in Produktion zu bringen. Wir filtern das Rauschen, übersetzen Probleme in Business-Impact und rollen Änderungen gemeinsam mit Ihrem Team im großen Maßstab aus.
Workload Reliability
Muster, die Services auch unter Last stabil halten. HA, Failure Domains und Graceful Degradation von Haus aus.
Security & Compliance
Least-Privilege, sinnvolle Defaults und kontinuierliche Hygiene. Posture Reviews mit priorisierten Fix-Listen und klaren Verantwortlichkeiten.
Kubernetes-Optimierung
Gesunde Cluster, planbare Kosten. Durchdachte Requests/Limits, Node Pools, Autoscaler und Bin-Packing.
Effizienz-Automatisierung
Policy-gesteuerte Aktionen für Scheduling, Snapshots, TTLs und Tag-Hygiene. Toil raus, Zuverlässigkeit bleibt.
Governance & Transparenz
Health, Kosten und Risiko an einem Ort. Klare Verantwortlichkeiten, direkt an Teams und Services gekoppelt.
FinOps-Alignment
Betrieb, der Budgets respektiert. Instance-Typen, Storage-Klassen und Datenpfade passend zu SLOs und Kosten gewählt.
Lernen Sie Ihr Team kennen
Was sind Forward Deployed Engineers?
Forward Deployed Engineers sind erfahrene Cloud-Architekten, die sich direkt in Ihr Team einklinken.
Anders als Support-Teams, die auf Tickets reagieren, oder Beratungen, die Reports abliefern und wieder verschwinden, arbeiten FDEs Seite an Seite mit Ihren Engineers.
Sie kennen Ihre Architektur, Ihren Geschäftskontext und Ihre Rahmenbedingungen.
Ihr Team
Eine Erweiterung Ihres Teams
Ein erfahrenes Team, das direkt an Ihrer Seite arbeitet.
Forward Deployed Engineering
Erfahrene Cloud-Architekten, fest in Ihr Team integriert. Sie arbeiten mit Ihren Engineers an Umsetzung, Tests und Deployment.
Customer Success Manager
Ihre persönliche Ansprechperson. Hält Prioritäten scharf, räumt Blocker aus dem Weg und macht Ergebnisse über alle Workstreams hinweg sichtbar.
Cloud Procurement
Navigiert durch Commitments, Rabatte und Programme – damit Sie das Beste aus AWS, Google Cloud oder Azure herausholen.
CloudOps – gemeinsam gemacht
Von "Wir sehen es" zu "Es ist in Prod gefixt"
Die meisten Tools schlagen Alarm. Wir helfen Ihnen, Fixes in Produktion zu bringen. DoiT filtert das Rauschen, übersetzt Probleme in Business-Impact und rollt Änderungen gemeinsam mit Ihrem Team im großen Maßstab aus.
Keine Alert-Müdigkeit mehr. Kein ständiges Springen zwischen Konsolen. Stattdessen klare Verantwortlichkeiten und messbare Ergebnisse.
GenAI in CloudOps
AI-Workloads wie Produktion betreiben
Schwankende Lasten, GPU-Scheduling, Model Drift, unberechenbare Kosten. Unser FDE-Team führt GenAI Ops wie jeden anderen kritischen Workload.

GPU-Effizienz
Unterausgelastete Inference- und Training-Runs erkennen. Accelerators ausgelastet halten – ohne Waste.

Scaling Patterns
Autoscaling-Strategien, abgestimmt auf LLMs und GenAI-Workloads.

Data Pipelines
Ingestion und Preprocessing härten, damit das Training nie stockt.
FinOps für AI
Token-Verbrauch, Provider-Kosten und Trade-offs auf einen Blick.

Resilience by Default
HA-Patterns, Failure Domains und Graceful Degradation von Anfang an.

Produktions-Validierung
Load Tests, Chaos Drills und Rollback-Pläne vor dem Go-live.
Reliability & Performance
Für Uptime unter echter Last konzipieren und betreiben
Mit Cloud Diagrams visualisieren Sie Well-Architected- und SRE-Prinzipien und setzen sie um, damit Ausfälle gar nicht erst entstehen.
- Right-Sizing und Auto-Scaling für reale Nachfrage, Saisons und Events
- Workloads sicher migrieren und modernisieren
- Load Tests, Chaos Drills und Rollback-Pläne inklusive
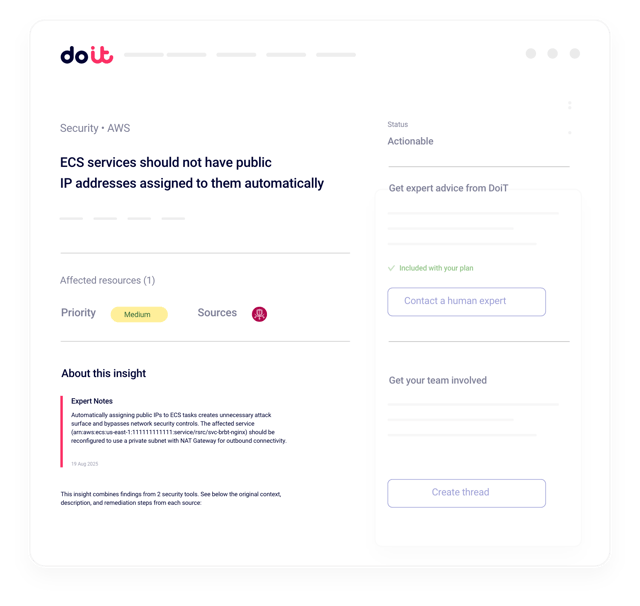
Security, die nicht ausbremst
Die Basics sauber aufsetzen – und Drift draußen halten
Priorisierte Fix-Listen mit Verantwortlichen und Zeitplan, sichtbar über Insights. Plattformnative Controls für IAM, Org Policies, Service Perimeters, KMS und Netzwerksegmentierung.
Baseline-Konfigurationen, Drift-Erkennung und Quick Wins automatisiert – so bleibt Security aktuell, ohne Teams auszubremsen.
Wir bekommen Cloud-Optimierungsexperten, die unsere Kosten spürbar senken, und gleichzeitig erfahrene Mentoren und Sparringspartner, die uns helfen, unsere Architektur weiterzuentwickeln und neue Ansätze auszuprobieren.
Alex Ischenko, VP Engineering at Ablefy
So arbeiten wir: eingebettet und hands-on
Keine Ticket-Queue. Kein Berater-Slidedeck. Forward Deployed Engineers arbeiten mit Ihrem Team in einem strukturierten Prozess, der echte Changes ausliefert.


von Reliability bis Kosten
Großes, globales Team
Minuten Erstberatung
AWS betreiben, als wäre es Ihr Beruf
Buchen Sie ein 15-minütiges Gespräch und sortieren Sie Ihre CloudOps-Prioritäten.