
La eligen los equipos de IA donde el gasto en GPU es crítico
Conéctate en minutos
Una cuenta de servicio. Visibilidad total sobre Nebius.
Conecta tu tenant de Nebius con una cuenta de servicio de solo lectura. DoiT ingiere automáticamente los datos de facturación, el uso de GPU y las métricas de Managed Kubernetes: sin agentes, sin cambios de código y sin reenviar facturas. En cuestión de horas ya estás viendo reportes unificados.
Lo que obtienes
Pensado para la realidad de correr IA en Nebius
Lo que realmente nos piden los líderes de FinOps y de plataformas de ML al conectar su entorno de Nebius.
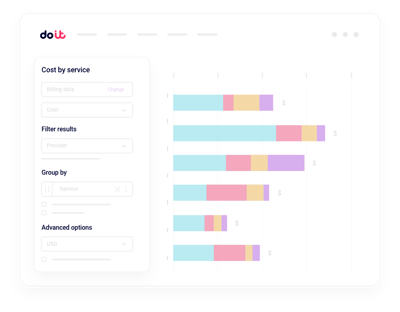
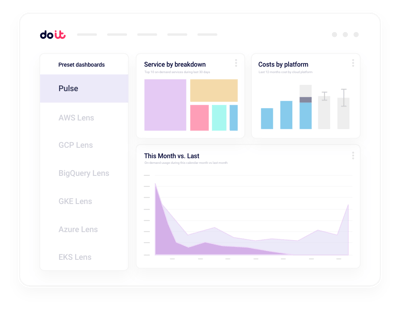
Reporting unificado de costos de IA
Segmenta el gasto de Nebius por proyecto, label, servicio o equipo sin tener que construir pipelines de facturación a medida.
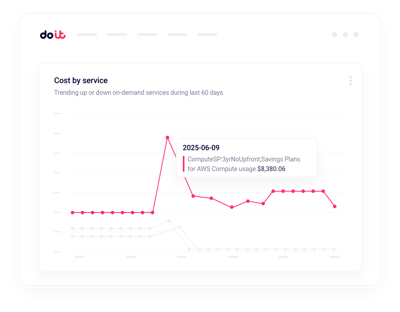
Anomalías en tiempo real
Recibe alertas sobre picos de facturación de GPU en minutos, no en horas.
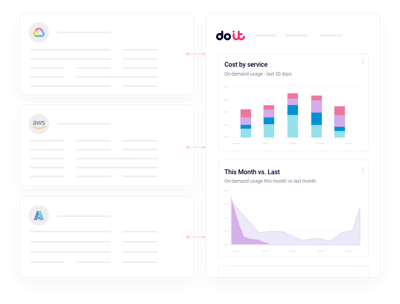
Insights de utilización de GPU
Detecta instancias H100 y H200 ociosas para que pagues por entrenar, no por esperar.
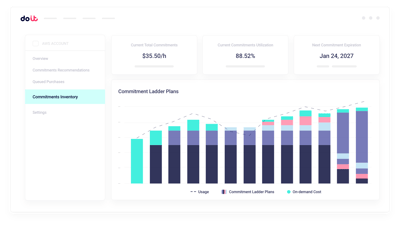
Right-sizing de clústeres
Ajusta el tamaño de tus clústeres de Slurm y Kubernetes a la demanda real de los workloads.
Visibilidad de storage y egress
Desenreda los cargos de Object Storage, snapshots y transferencia de datos que suelen esconderse detrás de los jobs de entrenamiento.
Gobernanza y presupuestos
Define políticas y presupuestos por equipo de investigación sin tener que perseguir la higiene de labels.
La consola de Nebius te dice cuánto gastaste. Cloud Intelligence™ te ayuda a hacer algo al respecto.
Mucho más que la consola de facturación de Nebius
Consolidación multiproyecto
Vistas consolidadas de todos tus proyectos de Nebius, con drilldown a cualquier equipo, clúster o workload.
Alertas de anomalías en tiempo real
Detección con machine learning en las dimensiones de servicio, proyecto y label, con envío a Slack o email.
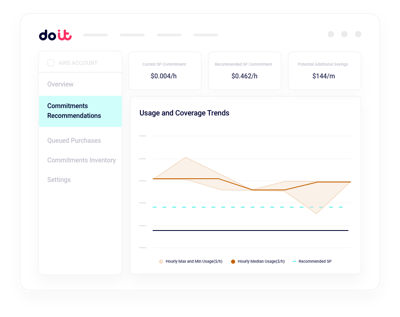
Planificación de capacidad de GPU
Modela la capacidad reservada de GPU frente a la demanda real de entrenamiento e inferencia antes de comprometerte.
Higiene de labels y asignaciones
Identifica el gasto sin etiquetar, aplica reglas de asignación y reparte los costos compartidos de IA tal como lo espera el área financiera.
Asignación de costos de Kubernetes
Desglosa el gasto de Managed Kubernetes por namespace, workload y label sin necesidad de exporters adicionales.
Forward Deployed Engineers
Arquitectos de nube de primer nivel que se suman como una extensión de tu equipo para implementar las optimizaciones.
Las empresas de alto crecimiento operan con DoiT Cloud Intelligence™
Ahorro promedio en los primeros 90 días
Tiempo promedio de implementación
“El enfoque de DoiT en la confiabilidad, sumado a la flexibilidad del sistema, nos permite optimizar de forma segura nuestros workloads de Amazon EKS sin que nuestros Engineers tengan que intervenir.”
Oren Ashkenazy
Director of DevOps and Cloud at Fiverr
¿Listo para conectar tu tenant de Nebius?
Pon tu gasto en GPU bajo la lupa.
Frequently asked
questions
¿Cómo obtengo mejor visibilidad de los costos de Nebius en varios proyectos?
Conecta tu tenant de Nebius una sola vez. Cloud Intelligence™ ingiere los datos de facturación de cada proyecto, para que puedas segmentar los costos por proyecto, label, servicio o equipo desde una sola vista, sin hojas de cálculo ni consolidaciones manuales.
¿Cuál es la mejor forma de integrar los datos de facturación de Nebius con Cloud Intelligence™?
Usa una cuenta de servicio de solo lectura con acceso a tus APIs de facturación y uso. DoiT se encarga de la ingesta, la normalización y el reporting detallado. La mayoría de los equipos queda operativa en un día.
¿Cómo puedo ver qué instancias de GPU o servicios de IA concentran la mayor parte de mi gasto?
Los reportes de costos y uso te permiten ir del gasto total hasta una instancia de GPU específica, un clúster de Managed Kubernetes o un bucket de Object Storage. Se puede filtrar por labels, proyectos o regiones sin escribir SQL.
¿Cómo puedo monitorear las anomalías de costos de Nebius en tiempo real?
La detección de anomalías corre de forma continua por servicios, proyectos y dimensiones de labels. Cuando algo se sale de lo normal —por ejemplo, un job de entrenamiento que quedó corriendo todo el fin de semana— recibes una alerta en Slack o email con la causa más probable.
¿Cómo mejoro la utilización de GPU y reduzco el tiempo ocioso?
DoiT identifica las instancias y clústeres de GPU subutilizados y señala los workloads que están aprovisionados pero no están entrenando. Obtienes recomendaciones accionables para reducir su tamaño, consolidarlos o apagar la capacidad ociosa.
¿Cómo obtengo mejor visibilidad de los costos de storage y egress de Nebius?
Los cargos de Object Storage, snapshots y transferencia de datos se desglosan por workload y origen, de modo que puedes saber qué pipeline de entrenamiento o endpoint de inferencia está generando el volumen.
¿En qué se diferencia Cloud Intelligence™ de la consola nativa de facturación de Nebius?
La consola de Nebius es una vista de facturación. Cloud Intelligence™ es una plataforma: visibilidad multicloud, recomendaciones proactivas, detección de anomalías en tiempo real, gobernanza, planificación de capacidad y acceso a Forward Deployed Engineers que te ayudan a actuar sobre lo que muestran los datos.
¿Mis datos están seguros cuando conecto mi tenant de Nebius?
Cloud Intelligence™ usa una cuenta de servicio de solo lectura con permisos mínimos. Nunca movemos workloads ni hacemos cambios sin tu aprobación, y la plataforma cuenta con certificación SOC 2 Type II.