
La référence des équipes IA pour qui la dépense GPU est critique
Connexion en quelques minutes
Un compte de service. Une visibilité Nebius totale.
Connectez votre tenant Nebius via un compte de service en lecture seule. DoiT ingère automatiquement les données de facturation, l'usage GPU et les métriques Managed Kubernetes — sans agent, sans modification de code, sans transfert de factures. Vos rapports unifiés sont prêts quelques heures après la connexion.
Ce que vous obtenez
Pensé pour la réalité de l'IA sur Nebius
Ce que les responsables FinOps et plateformes ML nous demandent concrètement lorsqu'ils connectent leur environnement Nebius.
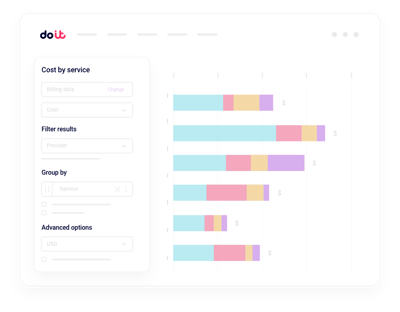
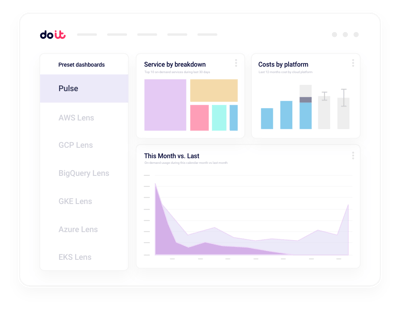
Reporting unifié des coûts IA
Ventilez vos dépenses Nebius par projet, label, service ou équipe, sans construire de pipelines de facturation sur mesure.
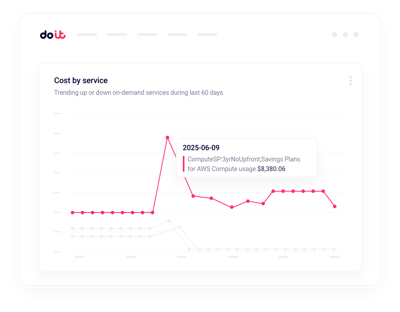
Anomalies en temps réel
Soyez alerté des pics de facturation GPU en quelques minutes, pas en quelques heures.
Analyse de l'usage GPU
Repérez les instances H100 et H200 inactives pour payer de l'entraînement, pas de l'attente.
Right-sizing des clusters
Alignez la taille de vos clusters Slurm et Kubernetes sur la demande réelle des workloads.
Visibilité sur le stockage et l'egress
Démêlez les frais d'Object Storage, de snapshots et de transfert de données qui se cachent derrière vos jobs d'entraînement.
Gouvernance et budgets
Définissez des politiques et des budgets par équipe de recherche, sans courir après l'hygiène des labels.
La console Nebius vous dit ce que vous avez dépensé. Cloud Intelligence™ vous permet d'agir.
Bien au-delà de la console de facturation Nebius
Consolidation multi-projets
Vues consolidées sur l'ensemble de vos projets Nebius, avec drilldown par équipe, cluster ou workload.
Alertes d'anomalies en temps réel
Détection par machine learning sur les dimensions service, projet et label, envoyée sur Slack ou par e-mail.
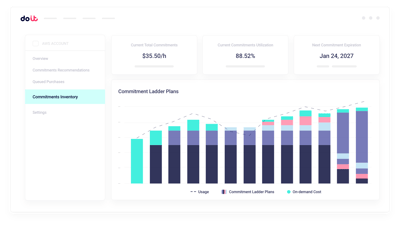
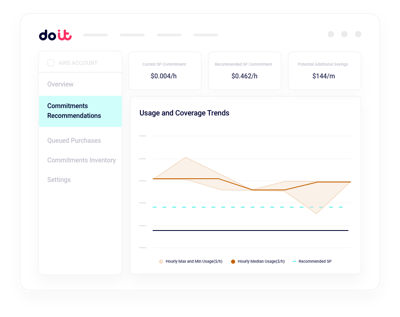
Planification de capacité GPU
Modélisez la capacité GPU réservée face à la demande réelle d'entraînement et d'inférence avant tout engagement.
Hygiène des labels et de l'allocation
Repérez les dépenses non labellisées, appliquez vos règles d'allocation et répartissez les coûts IA partagés comme la finance l'attend.
Allocation des coûts Kubernetes
Ventilez les dépenses Managed Kubernetes par namespace, workload et label, sans exporter supplémentaire.
Forward Deployed Engineers
Des architectes cloud d'exception qui interviennent comme une extension de votre équipe pour mettre en œuvre les optimisations.
Les entreprises en forte croissance s'appuient sur DoiT Cloud Intelligence™
D'économies moyennes durant les 90 premiers jours
Durée moyenne de mise en œuvre
“La fiabilité de DoiT, alliée à la flexibilité de la plateforme, nous permet d'optimiser en toute sécurité nos workloads Amazon EKS sans aucune intervention de nos Engineers.”
Oren Ashkenazy
Director of DevOps and Cloud chez Fiverr
Prêt à connecter votre tenant Nebius ?
Passez vos dépenses GPU au microscope.
Frequently asked
questions
Comment obtenir une meilleure visibilité sur les coûts Nebius au travers de plusieurs projets ?
Connectez votre tenant Nebius une seule fois. Cloud Intelligence™ ingère les données de facturation de chaque projet : vous ventilez vos coûts par projet, label, service ou équipe depuis une seule vue — sans tableurs ni consolidation manuelle.
Quelle est la meilleure façon d'intégrer les données de facturation Nebius à Cloud Intelligence™ ?
Utilisez un compte de service en lecture seule avec accès à vos API de facturation et d'usage. DoiT prend en charge l'ingestion, la normalisation et le reporting granulaire. La plupart des équipes sont opérationnelles en moins d'une journée.
Comment identifier les instances GPU ou services IA qui pèsent le plus dans mes dépenses ?
Les rapports Cost & Usage vous permettent de descendre du coût global jusqu'à une instance GPU, un cluster Managed Kubernetes ou un bucket Object Storage précis. Vous filtrez par labels, projets ou régions sans écrire une ligne de SQL.
Comment surveiller les anomalies de coûts Nebius en temps réel ?
La détection d'anomalies tourne en continu sur les services, les projets et les dimensions de labels. Dès qu'un élément sort de l'ordinaire — un job d'entraînement laissé actif tout le week-end, par exemple — vous recevez une alerte Slack ou e-mail avec la cause probable.
Comment améliorer l'utilisation GPU et réduire les temps d'inactivité ?
DoiT met en évidence les instances et clusters GPU sous-utilisés, en signalant les workloads provisionnés mais inactifs. Vous obtenez des recommandations concrètes pour réduire la taille, consolider ou arrêter les capacités inutilisées.
Comment obtenir une meilleure visibilité sur les coûts de stockage et d'egress Nebius ?
Les frais d'Object Storage, de snapshots et de transfert de données sont ventilés par workload et par source, afin d'identifier quel pipeline d'entraînement ou endpoint d'inférence génère le volume.
En quoi Cloud Intelligence™ se différencie-t-il de la console de facturation native de Nebius ?
La console Nebius est une vue de facturation. Cloud Intelligence™ est une plateforme : visibilité multicloud, recommandations proactives, détection d'anomalies en temps réel, gouvernance, planification de capacité et accès à des Forward Deployed Engineers qui vous aident à tirer parti des données.
Mes données sont-elles sécurisées lorsque je connecte mon tenant Nebius ?
Cloud Intelligence™ utilise un compte de service en lecture seule avec des permissions au plus juste. Nous ne déplaçons jamais de workloads et n'apportons aucune modification sans votre validation. La plateforme est certifiée SOC 2 Type II.