
Trusted by AI teams where GPU spend is mission-critical
Connect in minutes
One service account. Full Nebius visibility.
Connect your Nebius tenant with a read-only service account. DoiT ingests billing data, GPU usage, and Managed Kubernetes metrics automatically — no agents, no code changes, no forwarding of invoice data. You're looking at unified reports within hours of connecting.
What you get
Built for the realities of running AI on Nebius
The things FinOps and ML platform leaders actually ask us for when they connect their Nebius environment.
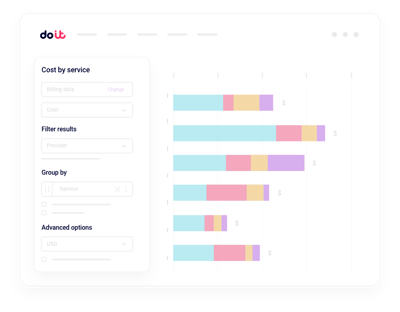
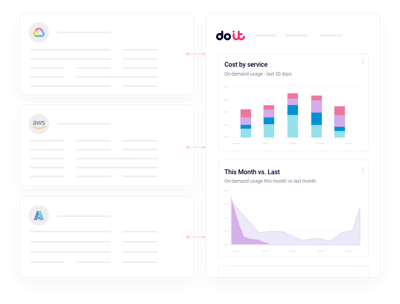
Unified AI cost reporting
Slice Nebius spend by project, label, service, or team without building custom billing pipelines.
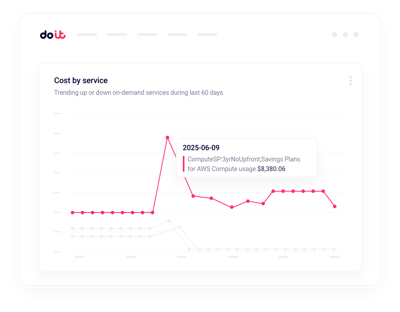
Real-time anomalies
Get alerted on GPU billing spikes in minutes, not hours.
GPU utilization insights
Spot idle H100 and H200 instances so you pay for training, not waiting.
Cluster rightsizing
Match Slurm and Kubernetes cluster size to real workload demand.
Storage and egress visibility
Untangle Object Storage, snapshot, and data transfer charges that hide behind training jobs.
Governance and budgets
Set policies and budgets per research team without chasing label hygiene.
The Nebius console tells you what you spent. Cloud Intelligence™ helps you do something about it.
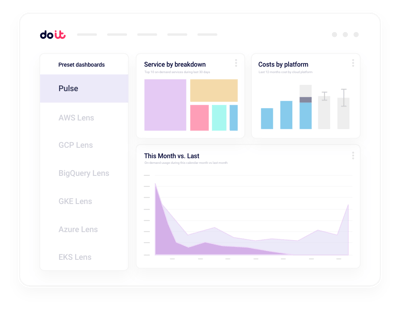
Beyond the Nebius billing console
Multi-project rollups
Consolidated views across every Nebius project, with drilldown into any team, cluster, or workload.
Real-time anomaly alerts
Machine-learning detection on service, project, and label dimensions, routed to Slack or email.
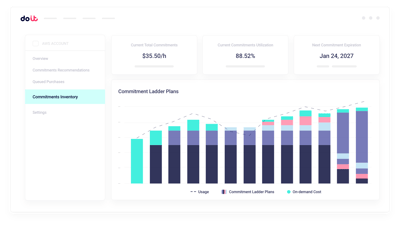
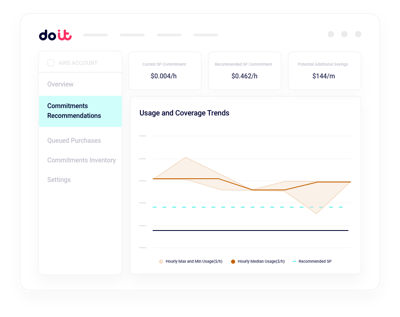
GPU capacity planning
Model reserved GPU capacity against actual training and inference demand before you commit.
Label and allocation hygiene
Find unlabeled spend, enforce allocation rules, and split shared AI costs the way finance expects.
Kubernetes cost allocation
Break down Managed Kubernetes spend by namespace, workload, and label without extra exporters.
Forward Deployed Engineers
World-class cloud architects who work as an extension of your team to implement optimizations.
Fast-growing companies run on DoiT Cloud Intelligence™
Avg. savings within first 90 days
Avg implementation time
“DoiT's focus on reliability, mixed with the system's flexibility, helps us safely optimize our Amazon EKS workloads with zero-touch from our engineers.”
Oren Ashkenazy
Director of DevOps and Cloud at Fiverr
Ready to connect your Nebius tenant?
Put your GPU spend under the microscope.
Frequently asked
questions
How do I get better visibility into Nebius costs across multiple projects?
Connect your Nebius tenant once. Cloud Intelligence™ ingests billing data for every project, so you can slice costs by project, label, service, or team from a single view — no spreadsheets, no manual rollups.
What's the best way to integrate Nebius billing data with Cloud Intelligence™?
Use a read-only service account with access to your billing and usage APIs. DoiT handles ingestion, normalization, and fine-grained reporting. Most teams are live within a day.
How can I see which GPU instances or AI services drive most of my spend?
Cost & Usage reports let you drill from top-level spend down to a specific GPU instance, Managed Kubernetes cluster, or Object Storage bucket. You can filter by labels, projects, or regions without writing SQL.
How can I monitor Nebius cost anomalies in real-time?
Anomaly detection runs continuously across services, projects, and label dimensions. When something looks off — say, a training job left running over the weekend — you get a Slack or email alert with the likely cause.
How can I improve GPU utilization and reduce idle time?
DoiT surfaces underutilized GPU instances and clusters, highlighting workloads that are provisioned but not training. You get actionable recommendations to downsize, consolidate, or shut down idle capacity.
How can I get better visibility into Nebius storage and egress costs?
Object Storage, snapshots, and data transfer charges are broken down by workload and source so you can tell which training pipeline or inference endpoint is generating the volume.
How is Cloud Intelligence™ different from the native Nebius billing console?
The Nebius console is a billing view. Cloud Intelligence™ is a platform: multicloud visibility, proactive recommendations, real-time anomaly detection, governance, capacity planning, and access to forward deployed engineers who help you act on what the data shows.
Is my data secure when I connect my Nebius tenant?
Cloud Intelligence™ uses a read-only service account with least-privilege permissions. We never move workloads or make changes without your approval, and the platform is SOC 2 Type II certified.