
GPUコストがビジネスを左右するAIチームに選ばれています
接続はわずか数分
サービスアカウント1つで、Nebiusのすべてを可視化。
読み取り専用のサービスアカウントをNebiusテナントにつなぐだけ。DoiTが請求データ、GPU使用状況、Managed Kubernetesのメトリクスを自動で取り込みます。エージェント導入もコード変更も、請求データの転送も不要。接続から数時間で、統合されたレポートをご確認いただけます。
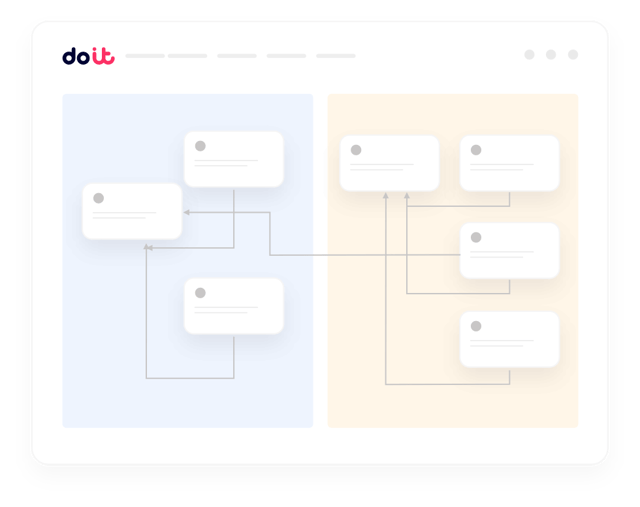
できること
Nebius上でAIを動かす現場のための機能群
Nebius環境をつないだFinOpsやMLプラットフォームのリーダーから、実際に寄せられる要望に応えます。
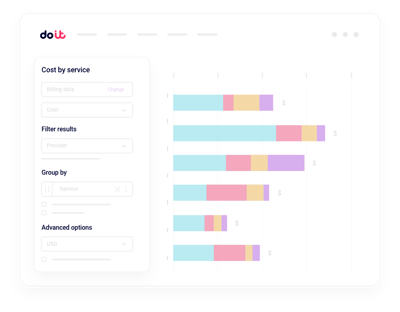
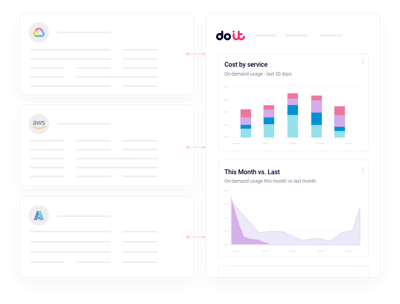
AIコストを一元的にレポート
独自の請求パイプラインを組まずに、Nebiusの支出をプロジェクト・ラベル・サービス・チーム単位で自在に切り分け。
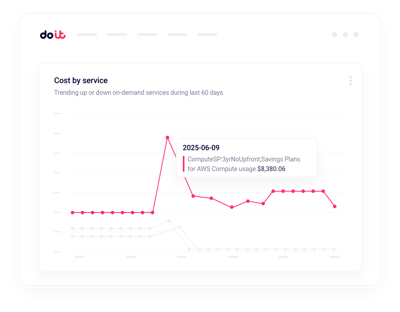
リアルタイム異常検知
GPU請求の急増を、数時間ではなく数分で通知。
GPU使用率のインサイト
アイドル状態のH100・H200インスタンスを洗い出し、待ち時間ではなく学習そのものに費用を。
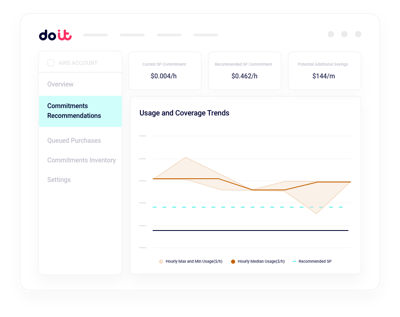
クラスターのライトサイジング
SlurmやKubernetesクラスターのサイズを、実際のworkload需要にぴたりと合わせます。
ストレージとエグレスを可視化
学習ジョブの裏に埋もれがちなObject Storage、スナップショット、データ転送の料金をひも解きます。
ガバナンスと予算管理
ラベル整備に追われることなく、研究チームごとにポリシーと予算を設定。
Nebiusコンソールが示すのは「いくら使ったか」。Cloud Intelligence™は「どう動くか」まで導きます。
Nebius請求コンソールの、その先へ
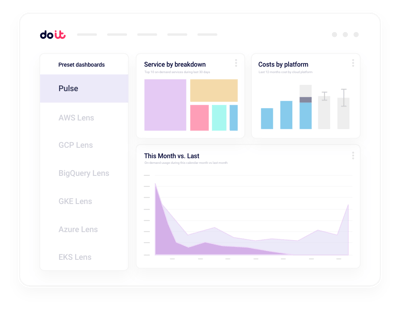
マルチプロジェクトの集約ビュー
すべてのNebiusプロジェクトを横断する統合ビュー。任意のチーム、クラスター、workloadまでドリルダウン可能。
リアルタイム異常アラート
サービス・プロジェクト・ラベルの各軸で機械学習が検知し、Slackやメールに即時通知。
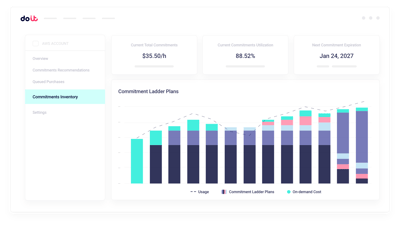
GPUキャパシティプランニング
commitmentsを決める前に、実際の学習・推論需要に照らして予約GPUキャパシティをシミュレーション。
ラベルとアロケーションの健全化
未ラベルの支出を洗い出し、アロケーションルールを徹底。共有AIコストを経理が納得する形で配賦します。
Kubernetesのコスト配賦
追加のエクスポーター不要で、Managed Kubernetesの支出を名前空間・workload・ラベル単位に分解。
Forward Deployed Engineers
お客様チームの一員として最適化を実装する、ワールドクラスのクラウドアーキテクト。
成長を加速する企業は、DoiT Cloud Intelligence™を選んでいます
最初の90日間の平均削減率
平均導入期間
“DoiTの信頼性へのこだわりとシステムの柔軟性のおかげで、Amazon EKSのworkloadをEngineersの手をわずらわせず、安全に最適化できています。”
Oren Ashkenazy
Director of DevOps and Cloud at Fiverr
Nebiusテナントを接続する準備はできましたか?
GPUコストを、徹底的に見える化。
Frequently asked
questions
複数プロジェクトにまたがるNebiusコストの可視性を高めるには?
Nebiusテナントを一度つなぐだけ。Cloud Intelligence™が全プロジェクトの請求データを取り込み、プロジェクト・ラベル・サービス・チーム単位のコストを1つのビューで切り分けられます。スプレッドシートも手作業の集計も不要です。
NebiusとCloud Intelligence™を連携させる最適な方法は?
請求および使用状況APIへのアクセス権を持つ読み取り専用サービスアカウントをご用意ください。データ取り込み、正規化、詳細なレポーティングはDoiTが担います。多くのチームが1日以内に稼働開始しています。
支出の大半を占めるGPUインスタンスやAIサービスを、どのように特定できますか?
Cost & Usageレポートで、全体支出から特定のGPUインスタンス、Managed Kubernetesクラスター、Object Storageバケットまでドリルダウン可能。SQLを書かずに、ラベル・プロジェクト・リージョンでフィルタリングできます。
Nebiusのコスト異常をリアルタイムで監視するには?
異常検知はサービス・プロジェクト・ラベルの各軸で常時稼働しています。週末に学習ジョブが動きっぱなしといった異変があれば、原因候補とともにSlackやメールに通知が届きます。
GPU使用率を高めてアイドル時間を減らすには?
DoiTは活用しきれていないGPUインスタンスやクラスターを可視化し、プロビジョニングされていながら学習に使われていないworkloadを浮き彫りにします。ダウンサイジング、統合、アイドル容量の停止など、すぐに実行できる推奨事項を提示します。
Nebiusのストレージやエグレスのコストを、より見える化するには?
Object Storage、スナップショット、データ転送の料金をworkloadとソース別に分解。どの学習パイプラインや推論エンドポイントが転送量を生んでいるのかを突き止められます。
Cloud Intelligence™はNebius純正の請求コンソールと何が違いますか?
Nebiusコンソールは請求のビューにとどまります。Cloud Intelligence™は、マルチクラウドの可視化、先回りの推奨、リアルタイム異常検知、ガバナンス、キャパシティプランニング、そしてデータから得た示唆の実行を伴走するForward Deployed Engineersまでを備えたプラットフォームです。
Nebiusテナントを接続したとき、データは安全に保たれますか?
Cloud Intelligence™は最小権限の読み取り専用サービスアカウントを使用します。お客様の承認なくworkloadを移動したり変更を加えたりすることは一切ありません。プラットフォーム自体もSOC 2 Type II認証を取得しています。