
A escolha dos times de IA onde cada GPU conta
Conecte em minutos
Uma service account. Visibilidade total do Nebius.
Conecte seu tenant Nebius usando uma service account somente leitura. A DoiT ingere automaticamente os dados de billing, o uso de GPU e as métricas do Managed Kubernetes — sem agentes, sem mexer no código e sem precisar encaminhar faturas. Em poucas horas após a conexão, você já está olhando para relatórios unificados.
O que você ganha
Feito para a realidade de quem roda IA no Nebius
O que líderes de FinOps e de plataformas de ML realmente pedem quando conectam o ambiente Nebius.
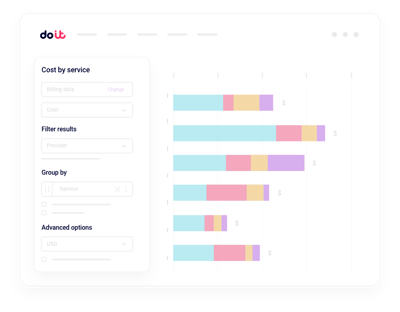
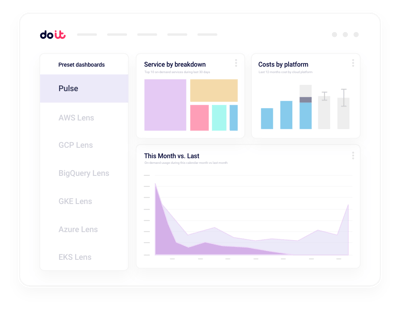
Relatórios unificados de custo de IA
Fatie os gastos do Nebius por projeto, label, serviço ou time sem precisar montar pipelines próprios de billing.
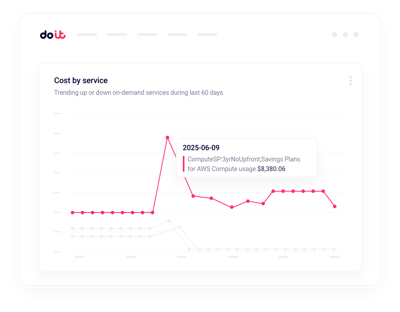
Anomalias em tempo real
Receba alertas sobre picos no faturamento de GPU em minutos, não em horas.
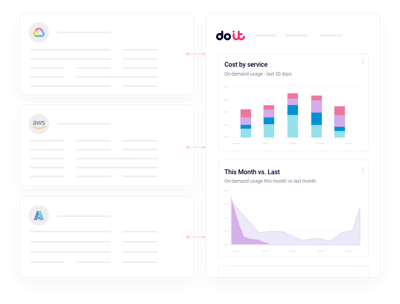
Insights de utilização de GPU
Identifique instâncias H100 e H200 ociosas e pague por treinamento, não por espera.
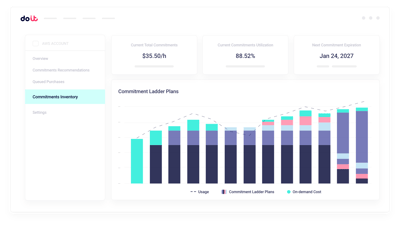
Right-sizing de clusters
Ajuste o tamanho dos clusters Slurm e Kubernetes à demanda real dos workloads.
Visibilidade de storage e egress
Destrinche cobranças de Object Storage, snapshots e transferência de dados que se escondem por trás dos jobs de treinamento.
Governança e budgets
Defina políticas e budgets por time de pesquisa sem precisar caçar labels mal aplicadas.
O console do Nebius mostra quanto você gastou. O Cloud Intelligence™ ajuda você a fazer algo a respeito.
Muito além do console de billing do Nebius
Consolidação entre projetos
Visões consolidadas de todos os projetos Nebius, com drill-down em qualquer time, cluster ou workload.
Alertas de anomalia em tempo real
Detecção por machine learning nas dimensões de serviço, projeto e label, entregue direto no Slack ou por e-mail.
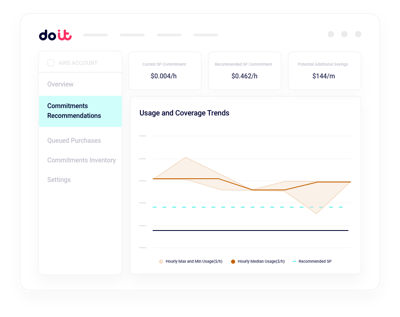
Planejamento de capacidade de GPU
Simule a capacidade reservada de GPU frente à demanda real de treinamento e inferência antes de assumir o compromisso.
Higiene de labels e alocação
Encontre gastos sem label, aplique regras de alocação e divida custos compartilhados de IA do jeito que o financeiro espera.
Alocação de custos no Kubernetes
Abra os gastos do Managed Kubernetes por namespace, workload e label sem precisar de exporters extras.
Forward Deployed Engineers
Arquitetos de nuvem de primeira linha que atuam como uma extensão do seu time para implementar as otimizações.
Empresas em rápido crescimento rodam no DoiT Cloud Intelligence™
Economia média nos primeiros 90 dias
Tempo médio de implementação
“O foco da DoiT em confiabilidade, somado à flexibilidade do sistema, nos permite otimizar com segurança nossos workloads no Amazon EKS sem que nosso time de engenharia precise colocar a mão.”
Oren Ashkenazy
Director of DevOps and Cloud na Fiverr
Pronto para conectar seu tenant Nebius?
Coloque seus gastos de GPU no microscópio.
Frequently asked
questions
Como consigo mais visibilidade dos custos do Nebius em vários projetos?
Conecte seu tenant Nebius uma única vez. O Cloud Intelligence™ ingere os dados de billing de cada projeto, e você fatia os custos por projeto, label, serviço ou time em uma visão única — sem planilhas, sem consolidações manuais.
Qual a melhor forma de integrar os dados de billing do Nebius ao Cloud Intelligence™?
Use uma service account somente leitura com acesso às APIs de billing e uso. A DoiT cuida da ingestão, da normalização e dos relatórios detalhados. A maioria dos times entra em operação em até um dia.
Como saber quais instâncias de GPU ou serviços de IA puxam a maior parte do gasto?
Os relatórios de Cost & Usage permitem ir do gasto total até uma instância de GPU específica, um cluster do Managed Kubernetes ou um bucket do Object Storage. Dá para filtrar por labels, projetos ou regiões sem escrever SQL.
Como monitorar anomalias de custo no Nebius em tempo real?
A detecção de anomalias roda continuamente em serviços, projetos e dimensões de label. Quando algo foge do padrão — por exemplo, um job de treinamento que ficou rodando o fim de semana todo — você recebe um alerta no Slack ou por e-mail com a provável causa.
Como melhorar a utilização de GPU e reduzir tempo ocioso?
A DoiT identifica instâncias e clusters de GPU subutilizados e destaca workloads que estão provisionados, mas sem treinar. Você recebe recomendações práticas para reduzir, consolidar ou desligar a capacidade ociosa.
Como ter mais visibilidade sobre custos de storage e egress no Nebius?
As cobranças de Object Storage, snapshots e transferência de dados são detalhadas por workload e origem, então dá para identificar exatamente qual pipeline de treinamento ou endpoint de inferência está gerando o volume.
Qual a diferença entre o Cloud Intelligence™ e o console nativo de billing do Nebius?
O console do Nebius é uma visão de billing. O Cloud Intelligence™ é uma plataforma: visibilidade multicloud, recomendações proativas, detecção de anomalias em tempo real, governança, planejamento de capacidade e acesso aos Forward Deployed Engineers, que ajudam você a agir sobre o que os dados mostram.
Meus dados ficam seguros ao conectar meu tenant Nebius?
O Cloud Intelligence™ usa uma service account somente leitura, com permissões de menor privilégio. Nunca movemos workloads nem fazemos alterações sem a sua aprovação, e a plataforma é certificada SOC 2 Type II.